
简历问题总结
Summary
一、c++基础
C++程序执行的内存空间结构

- 代码区:存放函数体的二进制代码,由操作系统进行管理的
- 全局区:存放全局变量和静态变量以及常量**(数据段+BSS区)**
- 数据段(data):用来存放显式初始化的全局变量或者静态(全局)变量,常量数据。
- BSS段(Block Started by Symbol): 存储未初始化的全局变量或者静态(全局)变量。编译器给处理成0;
- 堆区:由程序员分配和释放,若程序员不释放,程序结束时由操作系统回收;堆由于new/delete分配空间不连续,会产生碎片
- 栈区:由编译器自动分配释放, 存放函数的参数值,局部变量等;堆由于new/delete分配空间不连续,会产生碎片
在main执行之前和之后执行的代码可能是什么
main函数执行之前:
主要就是初始化系统相关资源:设置栈指针,进行所有全局对象的构造以及初始化工作, 将main函数的参数argc,argv等传递给main函数,然后才真正运行main函数
C++中,argc和argv是命令行参数的传递机制,用于向程序传递参数。
argc是指传递给程序的参数个数,包括程序名本身。它是一个整数类型变量。argv是一个指向字符指针数组的指针,每个字符指针指向一个传递给程序的参数字符串。
1 |
|
main函数执行之后:
全局对象的析构函数会在main函数之后执行,对全局变量和全局对象进行销毁操作
可以用 atexit 注册一个函数,它会在main 之后执行;
define 、inline、typedef 的区别
define:定义预编译时处理的宏,只是简单的字符串替换,没有类型检查
是在编译的预处理段起作用
可以用来防止头文件重复引用
不分配内存,给出的是立即数,有多少次使用就进行多少次替换
typedef:用来给现有的类型定义一个新的名称,方便程序中使用这种类型。
有对应的数据类型,是要进行判断的
是在编译、运行的时候起作用
在静态存储区中分配空间,在程序运行过程中内存中只有一个拷⻉
inline: C++ 中的函数修饰符,用来告诉编译器将函数内容直接嵌入到调用处,减少函数调用的开销。
inline是先将内联函数编译完成生成了函数体直接插入被调用的地方,减少了ܴ压栈,跳转和返回的操作。没有普通函数调用时额外开销;
内联函数是一种特的函数,会进行类型检查;
对编译器的一种请求,编译器有可能拒绝绝这种请求
#include的作用
#include 是一个预处理指令,在编译代码之前,将指定的头文件的内容插入到当前文件中
new 与 malloc
因为new是关键字,我们本应该无法修改new分配内存的方式。由于new在分配内存时,调用operator new函数,它会尝试从堆中分配指定大小的内存块,并返回指向分配内存的指针。如果分配成功,则返回一个非空指针;如果分配失败,无法满足内存需求,则返回一个空指针。
当 operator new 无法分配所需的内存时,它有两种处理方式:
- 返回空指针:在 C++98/03 中,
operator new在分配失败时返回空指针,表示内存分配失败。 - 抛出
std::bad_alloc异常:在 C++11 及以后的版本中,operator new在分配失败时抛出std::bad_alloc异常,表示内存分配失败。
**C++ Primer 一书上说这不是重载 new 和 delete 表达式(如 operator= 就是重载 = 操作符),因为 new 和 delete 是不允许重载的;
1 | int *p = new int[5]; |
| C | c++ | |
|---|---|---|
| 性质 | malloc/free是函数 | new/delete是操作符 |
| 初始化 | malloc不可以初始化 | new可以初始化 |
| 开辟空间的位置 | malloc开辟的空间在堆区 | new开辟的空间在自由存储区 |
| 开辟空间的大小 | malloc开辟空间时需要指定空间大小 | new开辟空间时只需要类型名,由编译器自己计算大小 |
| 成功返回值 | malloc申请成功返回void*型空间,需要使用时强转成其他类型,失败返回NULL | new申请成功返回对象指针,失败则抛出异常 |
| 扩容 | malloc开辟的空间如果不够用,可以使用realloc扩容 | new没有直接的扩容方式 |
| 是否调用构造/析构 | new在申请空间时,先调用malloc开辟空间,再调用构造函数进行初始化,在delete时会先调用析构函数清理对象,然后调用free释放空间;new运算符具有异常处理机制,可在发生错误时抛出异常,而malloc不具备此功能 |
new是一个运算符,new操作符本身是不能被重载的,但是可通过调用operator new()`函数来改变new操作符的行为,分配内存,然后调用了类的构造函数来创建对象
1 |
|
如果是带有⾃定义析构函数的类类型,⽤ new [] 来创建类对象数组,⽽⽤ delete来释放会发
⽣什么?
1 | class A {}; |
那么 delete pAa; 做了两件事:
- 调⽤⼀次 pAa 指向的对象的析构函数
- 调⽤ operator delete(pAa);释放内存
显然,这里只对数组的第一个类对象调用了析构函数,后面的两个对象均没调用析构函数,如果类对象中申请了大量的内存需要在析构函数中释放,而你却在销毁数组对象时少调用了析构函数,这会造成内存泄漏。
应该用:delete[] pAa;
我们经常要用到动态分配一个数组,也许是这样的:
1 | string *psa = new string[10]; //array of 10 empty strings |
上面在申请一个数组时都用到了 new [] 这个表达式来完成,按照我们上面讲到的 new 和 delete 知识,第一个数组是 string 类型,分配了保存对象的内存空间之后,将调用 string 类型的默认构造函数依次初始化数组中每个元素;第二个是申请具有内置类型的数组,分配了存储 10 个 int 对象的内存空间,但并没有初始化。
如果我们想释放空间了,可以用下面两条语句:
1 | delete [] psa; |
都用到 delete [] 表达式,注意这地方的 [] 一般情况下不能漏掉!我们也可以想象这两个语句分别干了什么:第一个对 10 个 string 对象分别调用析构函数,然后再释放掉为对象分配的所有内存空间;第二个因为是内置类型不存在析构函数,直接释放为 10 个 int 型分配的所有内存空间。
[浅谈 C++ 中的 new/delete 和 new]/delete[] - hazir - 博客园 (cnblogs.com)
malloc线程安全吗
在标准 C 库中,malloc 函数并不是线程安全的。多线程环境下,如果多个线程同时调用 malloc 分配内存,可能会导致竞争条件和内存相关的问题。为了在多线程环境下保证 malloc 的线程安全,可以采用以下几种方法:
- 使用互斥锁:在
malloc函数的实现中使用互斥锁来保护关键数据结构,确保只有一个线程可以同时进入malloc函数。这样可以避免多个线程同时访问分配内存的数据结构,解决竞争条件。 - 使用线程局部存储:在一些
malloc实现中,可以使用线程局部存储(Thread Local Storage,TLS)来避免多线程之间的竞争。每个线程拥有自己独立的内存池,从而避免了竞争条件。 - 使用多个内存池:为了减少锁竞争,可以为每个线程分配一个独立的内存池。当线程需要分配内存时,直接从自己的内存池中分配,不会与其他线程产生竞争。
- 使用内存池和自由列表:在一些内存管理库中,会使用内存池和自由列表的技术来提高多线程下
malloc的性能和线程安全性。每个线程拥有自己的内存池,并且会维护一个自由列表来管理已经释放的内存块,避免频繁调用系统的内存分配和释放函数。 - 使用其他的内存分配算法:除了标准的
malloc,还可以考虑使用其他的内存分配算法,如 tcmalloc、jemalloc 等,它们通常都提供了更高效和线程安全的内存管理功能。
1 |
|
volatile
volatile是C++中的一个关键字,用于告诉编译器不要对该变量进行优化,每次使用这个变量的时候都从内存中重新读取数据,以避免一些意外的行为。主要用于多线程编程、硬件编程等场景中。
具体来说,当变量被声明为volatile时,编译器不会对其进行优化,例如不会将多个读操作合并为一个,也不会将多个写操作合并为一个。这是因为volatile变量可能会被其他线程或外部设备修改,编译器无法预知其值,因此不能进行优化。
另外,volatile还可以用于防止编译器过度优化代码。例如,某些情况下,编译器可能会认为某个计算结果是不会改变的,从而将其缓存起来,导致实际运行时结果错误。在这种情况下,可以将变量声明为volatile,以告诉编译器该变量可能会被修改,从而防止过度优化。
下面是一个简单的例子,用于演示volatile的作用:
1 |
|
在上面的例子中,主线程和子线程都访问了同一个变量flag。如果不将flag声明为volatile,则编译器可能会将其缓存起来,从而导致子线程无法及时获取到flag的修改。将flag声明为volatile后,可以确保子线程可以及时获取到flag的修改,从而正常退出循环。
一个函数f(int a, int b)的b和a的地址关系?
在 C++ 中,函数的参数在栈上以参数的逆序(从右到左)依次入栈,也就是说,函数的第一个参数 a 先入栈,紧接着第二个参数 b 入栈。所以在函数 f(int a, int b) 中,b 的地址会比 a 的地址更靠近栈顶。
具体来说,在函数 f 被调用时,编译器会在栈上为参数 a 和 b 分配空间,并按照参数逆序依次将它们的值压入栈中。栈的增长方向是从高地址到低地址,因此 b 的地址会比 a 的地址更小。
前置++与后置++
1 | //前置++ |
后置返回对象而不是引⽤:因为后置为了返回旧值创建了⼀个临时对象,在函数结束的时候这个对象就会被销毁,如果返回引⽤,函数调用结束后临时对象被销毁而报错;a++是一个表达式不可以作为左值
处理⽤户的⾃定义类型: 最好使⽤前置++,因为他不会创建临时对象,进⽽不会带来构造和析构⽽造成的格外开销
在C++中,左值是可以出现在赋值语句左侧的表达式,左值必须是一个可以被修改的存储位置,如变量、数组元素、结构体成员等
左值引用与右值引用
左值引用和右值引用是C++11中引入的概念,用于支持移动语义和完美转发。在理解左值引用和右值引用之前,我们先需要理解左值和右值的概念。
左值(Lvalue指的是一个对象(变量)的标识符,它具有持久的内存地址,可以取地址(&)并且可以被赋值。
右值(Rvalue指的是那些不能被取地址的表达式,比如字面常量、临时对象和表达式求值的结果等。
在C++中,左值引用(Lvalue Reference)使用&符号来声明,用于引用一个左值,而右值引用(Rvalue Reference)使用&&符号来声明,用于引用一个右值。
下面是一个简单的示例,说明左值引用和右值引用的区别:
1 | c++Copy code |
在上面的示例中,当我们调用func(a)时,会调用左值引用版本的函数,因为a是一个左值。当我们调用func(2)时,会调用右值引用版本的函数,因为2是一个右值。
右值引用是C++11中引入的一种新的引用类型,它可以绑定到右值,例如临时对象、字面量等,右值引用主要用于支持移动语义和完美转发。移动语义可以避免不必要的内存拷贝,提高程序的性能。完美转发可以保留参数的类型信息,避免参数被隐式转换,提高代码的安全性和可维护性。
右值允许程序员更加细粒度的处理对象拷贝时的内存分配问题,提高了对临时对象和不需要的对象的利用率;
移动语义std::move()
std::move是将对象的状态或者所有权从一个对象转移到另一个对象,避免不必要内存拷贝;
std::move函数可以显示地将左值转换为右值引用;
使用move函数转交unique_ptr的所有权
1 | int*p1 = new int(56); |
std::move() 的底层操作非常简单,它的实现只是将传入的对象转换为右值引用,即将左值引用转换为右值引用。
1 | template <typename T> |
T&&表示std::move()接受一个右值引用或一个将亡值(可以被移动的对象)作为参数。std::remove_reference<T>::type用于去除T的引用,得到对象的实际类型。static_cast<typename std::remove_reference<T>::type&&>(t)将对象t强制转换为右值引用。
unique_ptr 独占指针,只能使用std::move()转移拥有权
1 |
|
完美转发std::forward<>
完美转发可以在函数调用过程中保留参数的类型信息,避免参数被隐式转换,提高代码的安全性和可维护性。
1 | template<typename T> |
上面的程序的运行结果:
1 | Lvalue ref |
当传入函数的参数是一个右值,而你要在函数内使用此参数时,必定会被转换成左值(因为你用了个形参来接收他),也就是这时候这个参数丢失了他本身的语义。std::forward 的作用就是“完美”的保持这个参数的语义;
MyString实现
例如,我们可以通过定义右值引用参数来实现移动语义:
1 |
|
string的基本用法
需要包含头文件<string.h>或
1 | strcpy(p, p1) 将p1拷贝到p |
size_t find ( const string& str, size_t pos = 0 ) const;
返回str在字符串中第一次出现的位置下标,pos为初始查找位置;
basic_string substr( size_type index, size_type num = npos );
substr()函数返回本字符串的一个子串,从index开始,长num个字符;
https://leetcode.cn/problems/fraction-addition-and-subtraction/
给定一个表示分数加减运算的字符串 expression ,你需要返回一个字符串形式的计算结果。
1 | class Solution { |
explicit
在C++中,explicit关键字可以用于修饰构造函数或者转换函数,表示禁止编译器进行隐式转换。如果一个构造函数被explicit修饰,则该构造函数不能用于隐式转换,只能用于显式转换
例如,对于下面的代码:
1 | class A { |
在调用func(10)时,由于A的构造函数被explicit修饰,编译器不会将10隐式转换为A类型,因此会报错。而调用func(A(10))时,由于是显式转换,因此可以通过编译
strcpy()
1 |
|
注意返回的是字符串的起始地址
1 | char* strcat(char* dest, const char* src) { |
指向指针的引用/指针
1 | void GetMemory1(char* p){ |
在函数GetMemory1中,参数p是传递进来的指针的拷贝,指针p的改变不会影响原始指针str,在分配内存的同时对p进行修改在GetMemory1函数结束后已经失效。因此,该代码会导致未定义的行为,因为尝试将值复制到未分配内存的指针str中,可能会导致崩溃或者出现意想不到的结果。
为了解决此问题,可以改为接收指向指针的引用,或者返回所分配的指针。如下:
接收指向指针的引用:
1 | void GetMemory2(char*& p){ |
返回所分配的指针:
1 | char* GetMemory3(void){ |
注意,使用malloc分配的内存应该在不使用时释放,以避免内存泄漏
这是一个使用指向指针的指针修改的示例代码,符合Google C++规范:
1 | void GetMemory2(char** p) { |
在这个示例中,GetMemory2()函数使用指向指针的指针char**作为参数,以便可以修改指针的值。在函数内部,我们使用malloc()函数分配了100个字节的内存,并将其赋值给*p。在Test2()函数中,我们声明了一个指向字符的指针char* str,并将其初始化为nullptr。然后,我们调用GetMemory2()函数,并将&str传递给它,以便可以修改指针的值。最后,我们使用strcpy()函数将字符串”hello world”复制到分配的内存中,并使用printf()函数打印该字符串
a++ 和 int a = b 在C++中是否是线程安全
a++ 和 int a = b 都不是线程安全的
a++:从C/C++语法的级别来看,这是⼀条语句,应该是原⼦的;但从编译器得到的汇编指令来看,其实不是原⼦的。
其⼀般对应三条指令,⾸先将变量a对应的内存值搬运到某个存器(如eax)中,然后将该存器中的值⾃增1,再将该寄存器中的值运回a代表的内存中;如果多个线程同时对同一个变量进行自增操作,就可能导致竞争条件(RaceCondition),从而导致不确定的结果。
int a = b; 从C/C++语法的级别来看,这是条语句应该是原⼦的;但从编译器得到的汇编指令来看,由于现在计算机CPU架构体系的限制,数据不能直接从内存某处运到内存另外⼀处,必须借寄存器中转,因此这条语句⼀般对应两条计算机指令,即将变量b的值运到某个寄存器(如eax)中,再从该寄存器搬运到变量a的内存地址中:
mov eax, dword ptr [b]
mov dword prt [a], eax
多个线程在执⾏这两条指令时,某个线程可能会在第⼀条指令执⾏完毕后被剥夺CPU时间⽚,切换到另⼀个线程⽽出现不确定的情况。
解决办法: C++11新标准提供了对整形变量原⼦操作的相关库,即std::atomic,这是⼀个模板类型
1 | template<class T> |
为了确保线程安全,可以使用互斥锁(Mutex)、信号量(Semaphore)等机制来保护关键代码段,同时只允许一个线程进入。这样可以避免多个线程同时访问和修改同一个变量,从而确保安全性和正确性
static
static 关键字的不同用法:
- 局部静态变量(Static Local Variables): 在函数内部声明的变量可以使用
static关键字进行修饰。这样的变量在==整个程序的生命周期内只会被初始化一次==,并且存储在==静态存储区==。它在函数调用结束后并不会被销毁,下次函数再次调用时会继续存在。 - 全局静态变量(Static Global Variables): ==在全局范围内声明的变量,也就是在任何函数外部声明的变量==,可以使用
static关键字进行修饰。这样的变量作用域仅限于声明它的文件,也就是说它在其他文件中是不可见的。同样,它也存储在静态存储区。 - 静态成员变量(Static Member Variables): 在类内部声明的静态成员变量==属于整个类而不是类的实例==。这些变量在所有
类的实例之间共享,存储在静态存储区。 - 静态成员函数(Static Member Functions):
类中的静态成员函数不属于任何类的实例,因此它不访问任何实例特定的数据。==静态成员函数可以被直接通过类名调用,而不需要创建类的实例==。(单例模式)
局部静态变量与全局静态变量区别: 两者的作用域不一样,前者的作用域局限于声明它们的函数,后者的作用域限于整个文件;
static 线程安全性:
static 变量本身并不是线程安全或线程不安全的,它的线程安全性取决于你的代码如何使用它。在多线程环境中,多个线程访问和修改同一个 static 变量可能会引发竞争条件和数据不一致的问题。为了保证线程安全性,你可能需要使用互斥锁等机制来保护 static 变量的访问和修改。
虚函数
C++中的虚函数是一种在基类中声明并在派生类中重写的函数。它们用于实现多态性,即通过基类的指针或引用调用派生类的方法,在运行时根据对象的实际类型来调用相应的函数;
析构函数是不是必须要为虚函数?
析构函数可以是虚函数,也可以不是虚函数。
析构函数为虚函数的情况:继承
当父类指针释放子类对象时,如果父类的析构函数不是虚函数,子类的析构函数可能调不到(指针类型是父类,所以直接调用父类的析构函数),从而导致内存泄漏。
既然这样,是不是C++默认的析构函数设计成虚函数更合适?答案是否定的,虚函数需要额外的虚函数表和虚表指针,占用额外的内存,如果类的设计不考虑继承,把析构函数设置成虚函数无疑是浪费内存。
为什么构造函数不能是虚函数
构造函数不能是虚函数的主要原因是,它们在对象被创建时执行,而虚函数是在对象已经被创建后才能被调用。如果将构造函数声明为虚函数,可能会导致程序的行为不确定和程序崩溃等问题。
因为对象在被创建时,还没有被指针所指定,也就不存在虚表,所以构造函数不能是虚函数。此外,虚函数的调用是由虚表指针控制的,而构造函数在创建对象时不需要虚表。
另外,构造函数的目的是初始化对象的数据成员,为对象的使用做好准备。由于构造函数不能被继承,因此也没有意义把构造函数声明为虚函数。
总之,构造函数不能是虚函数,虚函数的调用是由已经创建好的对象来调用的,而构造函数则是用于对象创建的初始化工作,两者间存在本质差异。
虚函数表指针是一个指向虚函数表的指针,它在类的构造函数中被初始化,指向类的虚函数表。
虚函数表是一个存储类中所有虚函数地址的数组,它在编译时被创建,存在于程序的只读数据区。¹
- 编译期:对含虚函数的类(如基类)创建虚函数表;
- 链接期:对继承体系中每个类创建自己的虚函数表,并在其中填入虚函数地址,包括继承自基类的虚函数。
- 虚函数表指针存储于对象中,其存储区域取决于对象的存储区域;
因此,虚函数表指针在类的构造函数中被初始化,而虚函数表是在编译时被创建,存在于程序的只读数据区。¹²
如何从虚函数表中查找到 vfunc1 的地址?
虚函数表中的内容是在编译的时候确定的,通过以下方式进行查找 (* p->vptr[n] )(p) 或者 (* (p->vptr)[n] )(p),它的解读是:通过类对象指针p找到虚指针vptr,再查找到虚函数表中的第n个内容,并将他作为函数指针进行调用,调用时的入参是p(式子中的第二个p),而这个p就是隐藏的this指针,这里的n也是在编译的时候确定的
作者: JuZi
链接: https://juzihhu.github.io/2022/08/27/cppFoundation/
来源: JuZi
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
纯虚函数的实现以及意义 为什么析构函数可以是纯虚函数
纯虚函数是一个没有实现的虚函数,用 “= 0” 表示。它的主要作用是作为基类的接口,让子类强制实现。
纯虚函数的意义是将这个类定义为抽象类,不能实例化对象,从而提供一种标准化的接口,让不同的派生类都能够按照同一种方式来实现它。这样,基类就可以将不同的派生类的实例看作相同的类型,从而提高了程序的可扩展性和可维护性。
析构函数可以是纯虚函数,这是因为当一个基类中含有纯虚析构函数时,说明这个类是个抽象类,不能直接进行实例化。而派生类中必须要实现这个析构函数,因为在派生类中必须要对其进行清理,否则会导致内存泄漏。
什么是虚继承
- 虚继承解决在多重继承时由于虚基类的复制带来的“菱形继承”问题。虚继承会使派生类只继承一个虚基类的一个实例,从而减少了重复继承
1 |
|
C++标准库中的 iostream 类就是⼀个虚继承的实际应⽤案例
iostream 从 istream 和 ostream 直接继承⽽来,⽽ istream 和 ostream ⼜都继承⾃⼀个共同的名为 baseios 的类,此时 istream 和 ostream 必须采⽤虚继承,否则将导致 iostream 类中保留两份baseios 类的成员。
shared_ptr线程是否安全?
std::shared_ptr 在单线程环境下是安全的,因为它会自动管理引用计数,确保在没有任何指针指向对象时,正确地删除对象。然而,std::shared_ptr 在多线程环境下需要特别注意,因为引用计数的更新和对象的删除可能涉及多个线程并发访问共享资源。
shared_ptr循环引用怎么解决
循环引用(Circular Reference)是指多个对象之间形成相互引用的情况,而 shared_ptr 在处理循环引用时可能导致内存泄漏,因为它使用引用计数来管理资源的释放。解决循环引用的常用方法是使用 weak_ptr 来打破循环引用链。
1 |
|
智能指针
shared_ptr
shared_ptr的实现机制是在拷⻉构造时使⽤同⼀份引⽤计数,当一个新的 shared_ptr 对象指向同一资源时,该资源的引用计数增加 1。当某一个对象生命周期结束时,引用计数减 1
1 | template<typename T> |
==这段代码中的 “operator bool() const” 是一个类型转换函数,用于将 shared_ptr 对象转换为 bool 值。在代码中,它的作用是判断指针指向的资源是否为 nullptr,如果是则返回 false,否则返回 true。==
这个转换函数的作用可以体现为:将 shared_ptr 对象看作一个布尔类型的值,如果指针指向的资源存在,则其值为 true,否则其值为 false。这个转换函数的实现方式也比较简洁,只需要判断指针是否为 nullptr 即可。
这样实现的好处是可以方便的在条件语句中使用 shared_ptr 类型的对象,例如在 if 语句中判断一个 shared_ptr 对象是否为空指针,而无需进行显式的比较。
使用方式示例:if (my_shared_ptr) {…} 假如 my_shared_ptr 指向的资源存在,则执行 if 语句中的代码块,否则不执行。
1 |
|
这段代码存在的内存泄漏问题是,new出来的对象没有被delete,导致内存泄漏。悬空指针问题是,p2指向的对象已经被p1释放,但是p2仍然指向该对象,从而导致悬空指针问题。解决办法是,使用智能指针来管理内存,可以避免内存泄漏和悬空指针问题
unique_ptr
unique_ptr禁止了拷贝构造和赋值构造, 是一种独占指针,它拥有内存,不允许多个指针指向同一份内存。这种指针通常在需要使用动态内存的地方使用。当一个 unique_ptr 被析构时,它拥有的内存也会被释放。
weak_ptr
weak_ptr是为了配合shared_ptr引⼊的⼀种智能指针
可以在不独占资源的情况下监视资源状态的指针,通常用于检查是否还存在对象的共享所有权
假设我们需要实现一个场景,我们需要创建一个 Manager 类来管理一些 Worker 类的对象实例。一个 Manager 可以拥有多个 Worker 实例,每个 Worker 实例必须知道他的 Manager 是谁,但是每个 Worker 实例并不拥有属于 Manager 的所有权。
1 |
|
在这段代码中,当Manager类的智能指针被销毁时,实际上是指该对象所指向的内存空间被释放了,但是Worker类中保存了一个对该Manager对象的shared_ptr引用,引用计数并没有因为对象被销毁而降为0,从而导致了内存泄漏。
具体来说,对于Manager类中的vector容器,它是以shared_ptr的形式存储Worker对象的智能指针的。这意味着,在vector容器使用push_back等操作时,会递增Worker对象的引用计数。因此,在Manager对象被销毁时,Worker对象的引用计数不为0,因为它们仍然在vector容器中以shared_ptr的形式存在,从而导致了内存泄漏。
当使用智能指针时,需要特别注意避免循环引用现象。通过使用weak_ptr等手段,可以避免循环引用导致的内存泄漏问题。
lambda表达式
lambda表达式是一种C++11引入的匿名函数特性,它允许我们在需要函数的地方直接定义一个函数对象,而不必为其创建一个具名函数。lambda表达式的语法如下:
1 | [capture](parameters) -> return_type { // function body} |
1 |
|
谓词(Predicate)是一个用于判断某个条件是否成立的函数或者函数对象
lambda表达式[target](int x) -> bool { return x == target; }就是一个谓词。它接受一个int类型的参数x,表示vector中的一个元素,然后返回一个布尔值,表示这个元素是否等于目标值target
当使用引用捕获时,需要注意以下几点:
- 确保在Lambda表达式的有效期内,被捕获的变量仍然有效。避免在Lambda表达式内部使用已经超出作用域的变量引用。
- 注意捕获变量的生命周期问题。如果被捕获的变量在Lambda表达式执行完毕后会被销毁,那么在Lambda表达式内部就不能持续引用这些变量,否则会引发未定义行为。
- 当通过引用捕获一个局部变量时,需要确保在捕获列表中使用的变量确实存在,并且在Lambda表达式执行期间没有被销毁。
1 |
|
在计算机科学中,闭包(closure)是指一个函数,它包含了它所在作用域中的变量。lambda表达式是一种匿名函数,可以捕获它所在作用域中的变量。因此,lambda表达式可以被认为是闭包。
以下是闭包的几个应用场景:
- 回调函数:闭包可以用来实现回调函数。回调函数是一种在某个事件发生时被调用的函数。
- 延迟求值:闭包可以用来实现延迟求值。延迟求值是一种在需要时才计算表达式的值的技术。
- 函数式编程:闭包是函数式编程的基础。函数式编程是一种基于函数的编程范式。
auto和decltype的区别
auto是通过编译器计算变量的初始值来推断类型,而decltype同样也是通过编译器来分析表达式进而得到它的类型,但是它不用将表达式的值计算出来。auto将变量的类型和初始值绑定在一起,而decltype将变量的类型和初始值分开;虽然auto的书写更加简洁,但decltype的使用更加灵活。auto可以用于追踪返回类型,可以让编译器自动推导函数返回值的类型;而decltype(auto)可以让编译器自动推导函数返回值的类型,并且可以保留引用类型。auto可以用于迭代器,可以让编译器自动推导迭代器的类型;而decltype可以用于变量声明,可以让编译器自动推导变量的类型。
下面是一个代码示例:¹
1 |
|
内存泄漏&悬挂指针(野指针)的危害及避免
内存泄漏:动态申请的内存空间没有正常释放,但是也不能正确使用的情况;
程序循环new创建出的对象没有及时delete掉,导致内存泄漏。
delete掉一个void* 类型的指针,导致没有调用到对象的析构函数,析构的所有清理工作都没有去执行从而导致内存的泄漏
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25class Object {
private:
void* data;
const int size;
const char id;
public:
Object(int sz, char c):size(sz), id(c){
data = new char[size];
cout << "Object() " << id << " size = " << size << endl;
}
~Object(){
cout << "~Object() " << id << endl;
delete []data;
}
};
int main() {
Object* a = new Object(10, 'A');//Object*指针指向一个Object对象;
void* b = new Object(20, 'B');//void*指针指向一个Object对象;
delete a;//执行delete,编译器自动调用析构函数;
delete b;//执行delete,编译器不会调用析构函数,导致data占用内存没有得到回收;
cout << "Press any key to continue... ..." << endl;
getchar();
return 0;
}
野指针:指向已经删除的对象或者申请访问受限内存区域的指针
指针变量未初始化:指针变量在被创建未初始化时,并不是空指针,它的缺省值是随机的,会乱指一气。所以指针变量在创建同时就应对其进行初始化,要么将指针设置为NULL,要么让其指向一个合法的内存。
指针释放之后未置空:有时指针在free或者delete之后未赋值NULL,有可能被误以为是合法的指针,不能进关注free和delete后的指针名,他们只是将指针所指向的内存空间释放掉而已,但并没有把指针自身消灭,此时,指针指向的就是“垃圾”内存。被释放掉内存空间的指针应该立即将其置为NULL,防止产生野指针。
指针操作超越变量作用域
1 | class A { |
由于a的生命周期只是在void Test(void)函数内部,函数结束时a将被析构,所以在函数外使用指针p指向的内存空间已经被释放了,所以p已经是野指针了
Vector
vector底层实际是泛型的动态类型顺序表,因此其底层实际是一段连续的空间。在SGI-STL的vector中,实际在底层使用三个指针指向该段连续空间的,如下:
start指向空间的起始位置,finish指向最后一个元素的下一个位置,end_of_storage指向空间的末尾。
| 语法格式 | 用法说明 |
|---|---|
| iterator insert(pos,elem) | 在迭代器 pos 指定的位置之前插入一个新元素elem,并返回表示新插入元素位置的迭代器。 |
| iterator insert(pos,n,elem) | 在迭代器 pos 指定的位置之前插入 n 个元素 elem,并返回表示第一个新插入元素位置的迭代器。 |
| iterator insert(pos,first,last) | 在迭代器 pos 指定的位置之前,插入其他容器(不仅限于vector)中位于 [first,last) 区域的所有元素,并返回表示第一个新插入元素位置的迭代器。 |
| iterator insert(pos,initlist) | 在迭代器 pos 指定的位置之前,插入初始化列表(用大括号{}括起来的多个元素,中间有逗号隔开)中所有的元素,并返回表示第一个新插入元素位置的迭代器。 |
1 | std::vector<int> demo{1,2}; |
vector扩容与迭代器失效
注意结合指针使用时的情况
std::vector 可以在中间删除元素。你可以使用 erase 函数来删除指定位置的元素
删除位置索引为2的元素 vec.erase(vec.begin() + 2);
当使用 vector 的 erase 函数删除元素时,会导致迭代器失效,因为删除元素后,容器的大小改变了,原先的迭代器可能会指向无效的位置,从而导致未定义的行为。
为了解决这个问题,可以使用以下方法:使用返回值:erase 函数返回一个指向被删除元素之后元素的迭代器,可以在删除后将迭代器更新为返回的迭代器。
1 | std::vector<int> myVector = {1, 2, 3, 4, 5}; |
当向vector中插入元素时,如果元素有效个数size与空间容量capacity相等时,vector内部会触发扩容机制:
- 开辟新空间
- 拷贝元素
- 释放旧空间
如何避免扩容导致效率低
在插入之前,可以预估vector存储元素的个数,reserve()提前将底层容量开辟好即可。
选择以倍数方式扩容
理想的分配方案是在第N次扩容时如果能复用之前N-1次释放的空间,linux下是按照2倍的方式扩容的,而vs下是按照1.5倍的方式扩容的。
vector扩容,resize和reserve的区别
resize方法用于调整std::vector中元素的个数,可以增加或减少元素的数量。当使用resize增加元素的数量时,新添加的元素会被初始化为默认值(对于基本数据类型,会被初始化为 0);如果
resize减少元素数量,多余的元素会被删除。reserve方法用于预留std::vector的容量,但不改变元素的数量。当使用reserve方法预留容量时,std::vector会分配足够大的内存来容纳指定的元素数量,但并不初始化这些元素。如果
reserve分配的容量大于当前容量,会触发扩容,重新分配内存,并将现有元素复制到新的内存空间中。
push_back和emplace_back
push_back() 向容器尾部添加元素时,首先会创建这个元素,然后再将这个元素拷贝或者移动到容器中(如果是拷贝的话,事后会自行销毁先前创建的这个元素);
emplace_back() 在实现时,则是直接在容器尾部创建这个元素,省去了拷贝或移动元素的过程;
https://zhuanlan.zhihu.com/p/610294692
1 | /** |
const 成员函数
const成员函数通过在函数声明后加上const关键字来标识。例如:void func() const;- 在类中,如果一个成员函数不会修改对象的状态,可以将其声明为
const成员函数。在const成员函数中,不能修改任何非mutable成员变量。
C++类型转换
旧式风格的类型转换
1 | type(expr); // 函数形式的强制类型转换 |
现代C++风格的类型转换
1 | cast-name<type>(expression) |
cast-name有static_cast,dynamic_cast,const_cast和reinterpret_cast四种,表示转换的方式。
static_cast
不提供运行时的检查,需要在编写程序时确认转换的安全性。用于进行比较“自然”和低风险的转换,如基本数据类型之间的转换、把void指针转换成目标类型的指针;
1 | int i, j; |
dynamic_cast
dynamic_cast会专门用于将多态基类的指针或引用强制转换为派生类的指针或引用,而且能够检查转换的安全性。对于不安全的指针转换,转换结果返回 NULL 指针。
其他三种都是编译时完成的,dynamic_cast 是运行时处理的,运行时要进行类型检查
不能用于内置的基本数据类型的强制转换
dynamic_cast 要求 <> 内所描述的目标类型必须为指针或引用。dynamic_cast 转换如果成功的话返回的是指向类的指针或引用,转换失败的话则会返回 nullptr
在类的转换时,在类层次间进行上行转换(子类指针指向父类指针)时,dynamic_cast 和 static_cast 的效果是一样的
使用 dynamic_cast 进行转换的,基类中一定要有虚函数,否则编译不通过
const_cast
const_cast用于移除类型的const、volatile和__unaligned属性
__unaligned修饰的指针或引用允许访问未对齐的内存位置,默认情况下,C/C++要求所有数据的内存地址是其类型大小的整数倍,如果不满足对齐要求则会触发未定义行为。加上__unaligned可以取消这一要求,访问未对齐内存。
1 | const string s = "Inception"; |
reinterpret_cast
在编译期完成,可以转换任何类型的指针,所以极不安全;
二、计算机网络
基础篇
键入网址到网页显示,期间发生了什么?
- 解析 URL获取 Web 服务器和请求的资源路径,生成发送给
Web服务器的HTTP请求信息; - DNS域名解析,查询服务器域名对应的 IP 地址;(先查本地域名缓存->本地DNS 服务器)
- 通过 DNS 获取到 IP 后,应用程序(浏览器)通过调用 Socket 库来委托操作系统中的协议栈完成 HTTP 的传输工作;协议栈的上半部分有两块,分别是负责收发数据的 TCP 和 UDP 协议,这两个传输协议会接受应用层的委托执行收发数据的操作;协议栈的下面一半是用 IP 协议控制网络包收发操作
- 三次握手建立连接后开始TCP 传输数据;
- 提供TCP/IP四层协议对请求信息进行层层封装,从网卡经过交换机和路由器转发到达服务器,服务器对数据包层层解封,最后解析来自客户端的请求,生成HTTP响应报文再经过层层封装发送到客户端;
请问公网服务器的 Mac 地址是在什么时机通过什么方式获取到的?
在发送数据包时,如果目标主机不是本地局域网,填入的 MAC 地址是路由器,也就是把数据包转发给路由器,路由器一直转发下一个路由器,直到转发到目标主机的路由器,发现目标 IP 地址是自己局域网内的主机,就会 ARP 请求获取目标主机的 MAC 地址,从而转发到这个服务器主机。
转发的过程中,源 IP 地址和目标 IP 地址是不会变的(前提:没有使用 NAT 网络的),源 MAC 地址和目标 MAC 地址是会变化的
HTTP篇
能否详细解释「HTTP」?
全称为超文本传输协议,HTTP 是一个在计算机世界里专门在「两点」之间「传输」文字、图片、音频、视频等「超文本」数据的「约定和规范」
HTTP 常见的状态码有哪些?
2xx 类状态码表示服务器成功处理了客户端的请求,
3xx 类状态码表示客户端请求的资源发生了变动,需要客户端用新的 URL 重新发送请求获取资源,也就是重定向。
4xx 类状态码表示客户端发送的报文有误,服务器无法处理,也就是错误码的含义。
- 「400 Bad Request」表示客户端请求的报文有错误,但只是个笼统的错误。
- 「403 Forbidden」表示服务器禁止访问资源,并不是客户端的请求出错。
- 「404 Not Found」表示请求的资源在服务器上不存在或未找到,所以无法提供给客户端。
5xx` 类状态码表示客户端请求报文正确,但是服务器处理时内部发生了错误,属于服务器端的错误码。
- 「500 Internal Server Error」与 400 类型,是个笼统通用的错误码,服务器发生了什么错误,我们并不知道。
- 「501 Not Implemented」表示客户端请求的功能还不支持,类似“即将开业,敬请期待”的意思。
- 「502 Bad Gateway」通常是服务器作为网关或代理时返回的错误码,表示服务器自身工作正常,访问后端服务器发生了错误。
- 「503 Service Unavailable」表示服务器当前很忙,暂时无法响应客户端,类似“网络服务正忙,请稍后重试”的意思
HTTP 常见字段有哪些?
Host 字段:客户端发送请求时,用来指定服务器的域名。
Content-Length 字段:表明本次回应的数据长度
Connection 字段:最常用于客户端要求服务器使用「HTTP 长连接」机制,以便其他请求复用
Content-Type 字段用于服务器回应时,告诉客户端,本次数据是什么格式
客户端请求的时候,可以使用 Accept 字段声明自己可以接受哪些数据格式。
Content-Encoding 字段:说明数据的压缩方法。表示服务器返回的数据使用了什么压缩格式
1 | Host: www.A.com |
GET 和 POST 有什么区别?
从 RFC 规范定义的语义来分析:
GET 的语义是从服务器获取指定的资源,这个资源可以是静态的文本、页面、图片视频等。GET 请求的参数位置一般是写在 URL 中;可以理解为「只读」操作
POST 的语义是根据请求负荷(报文body)对指定的资源做出处理,具体的处理方式视资源类型而不同,POST 请求携带数据的位置一般是写在报文 body 中,例如提交留言或者注册就是执行一次post请求;
HTTP 与 HTTPS 有哪些区别?
HTTP 是超文本传输协议,信息是明文传输,存在安全风险的问题,HTTPS 就是在 HTTP 与 TCP 层之间增加了 SSL/TLS 安全传输层;
HTTP 连接建立相对简单, TCP 三次握手之后便可进行 HTTP 的报文传输。而 HTTPS 在 TCP 三次握手之后,还需进行 SSL/TLS 的握手过程,才可进入加密报文传输。
两者的默认端口不一样,HTTP 默认端口号是 80,HTTPS 默认端口号是 443。
HTTPS 协议需要向 CA(证书权威机构)申请数字证书,来保证服务器的身份是可信的。
可以通过哈希算法来保证消息的完整性;
可以通过数字签名来保证消息的来源可靠性(能确认消息是由持有私钥的一方发送的);
HTTP/1.1 和 HTTP/2.0 传输协议使用的是 TCP 协议,而到了 HTTP/3.0 传输协议改用了 UDP 协议。
HTTPS 一定安全可靠吗?
HTTPS 协议本身到目前为止还是没有任何漏洞的,但是会有中间人攻击的情况发生,本质上是利用了客户端的漏洞(用户点击继续访问或者被恶意导入伪造的根证书),并不是 HTTPS 不够安全。
客户端请求连接可能会有中间人服务器存在的情况。中间人服务器与客户端在 TLS 握手过程中,实际上发送了自己伪造的证书给浏览器,而这个伪造的证书是能被浏览器(客户端)识别出是非法的,于是就会提醒用户该证书存在问题。
如果用户执意点击「继续浏览此网站」,相当于用户接受了中间人伪造的证书,那么后续整个 HTTPS 通信都能被中间人监听了。
如果你的电脑中毒了,被恶意导入了中间人的根证书,那么在验证中间人的证书的时候,由于你操作系统信任了中间人的根证书,那么等同于中间人的证书是合法的,这种情况下,浏览器是不会弹出证书存在问题的风险提醒的。
HTTP/1.0、HTTP/1.1、HTTP/2、HTTP/3演变
- HTTP/1.1相比HTTP/1.0性能上的改进:
- 使用TCP长连接的方式改善了HTTP/1.0短连接造成性能开销
- 支持管道(pipeline)网络传输,只要第一个请求发出去了,不必等其回来,就可以发第二个请求出去,可以减少整体的响应时间
- HTTP/1.1 自身的性能瓶颈:
- 请求/响应头部(Header)未经压缩就发送,首部信息越多延迟越大。只能压缩Body的部分
- 发送冗长的首部。每次互相发送相同的首部造成的浪费较多
- 服务器是按请求的顺序响应的,如果服务器响应慢,会招致客户端一直请求不到数据,也就是队头阻塞
- 没有请求优先级控制
- 请求只能从客户端开始,服务器只能被动响应
HTTP/2协议是基于HTTPS的,所以HTTP/2的安全性是有保障的。
- HTTP/2相比HTTP/1.1性能上的改进:
HTTP/2会压缩头(Header),如果你同时发送多个请求,他们的头是一样的或者是相似的,那么协议会帮你消除重复的部分。
HTTP/2不再像HTTP/1.1里的纯文本的报文,而是全面采用了二进制格式。头信息和数据体都是二进制,并且统称为帧(frame):头信息帧和数据帧。
HTTP/2的数据包不是按顺序发送的,同一个连接里面连续的数据包,可能属于不同的回应。客户端还可以指定数据流的优先级。
HTTP/2的连接可以并发多个请求(多路复用),而不用按照顺序一一对应。移除了HTTP/1.1中的串行请求,不需要排队等待,不会再出现「队头阻塞」问题。
比如:在一个TCP连接里,服务器收到了客户端A和B的两个请求,如果发现A处理过程非常耗时,于是就回应A请求已经处理好的部分,接着回应B请求,完成后,再回应A请求剩下的部分。
服务器推送,HTTP/2在一定程度上改善了传统的「请求-应答」工作模式,服务不再是被动地响应,也可以主动向客户端发送消息。
比如:在浏览器刚请求HTML的时候,就提前把可能用到的JS、CSS文件等静态资源主动发给客户端,减少延时的等待,也就是服务器推送(Server Push,也叫Cache Push)
- HTTP/2有哪些缺陷?HTTP/3做了哪些优化?
- HTTP/2主要的问题在于:多个HTTP请求在复用一个TCP连接,下层的TCP协议是不知道有多少个HTTP请求。所以一旦发生了丢包现象,就会触发TCP的重传机制,这样在一个TCP连接中的所有的HTTP请求都必须等待这个丢了包被重传回来。(区别:HTTP/1.1 的管道传输中,如果有一个请求阻塞,那么队列请求也统统被阻塞住了)
- HTTP/3 把HTTP下层的TCP协议改成了UDP
DNS详细说说?DNS用的什么协议?
域名解析协议(DNS,Domain Name System),用于将域名和 IP 地址相互映射
DNS使用TCP协议与UDP协议视情况而定,一般来说是认为使用的UDP协议,当客户端向DNS查询域名,一般不会超过512字节,而且无连接的过程更安全也更快;
区域传输时需要使用TCP协议,即进行与主域名服务器进行查询以确认数据是否有效,用TCP则是依赖了其可靠性;
长连接和短连接
长连接和短连接都是指客户端和服务器之间的TCP连接的持续时间。
短连接是指客户端与服务器之间的TCP连接只建立一次,数据传输完成后立即关闭连接。每次客户端请求都需要重新建立连接,适用于一些对实时性要求不高的场景,例如HTTP协议中的短连接。
长连接是指客户端与服务器之间的TCP连接可以持续一段时间,不会因为一次数据传输完成就立即关闭连接。适用于需要频繁交互数据的场景,例如在线聊天、视频会议等。在长连接中,客户端和服务器之间可以保持会话状态,减少了重复连接和认证的开销,提高了网络效率。但是,长连接也会占用服务器资源,需要根据实际情况进行权衡和选择
session与cookie的区别
Session和Cookie是在Web开发中用于维护用户状态和数据的两种机制,但它们有一些区别:
Cookie:
- 存储位置: Cookie是存储在客户端(浏览器)的小型文本文件中。
- 大小限制: Cookie的大小一般受到浏览器的限制,通常为4KB左右。
- 持久性: 可以设置Cookie的过期时间,可以是会话级的(浏览器关闭后失效)或持久的(在指定时间后失效)。
- 跨域: Cookie可以在同一个域名下的不同页面之间共享,但有域名和路径限制。
- 安全性: Cookie的内容可以被用户修改,因此不适合存储敏感信息。
Session:
- 存储位置: Session是存储在服务器端的数据存储区域,通常存储在内存中,也可以存储在数据库或文件中。
- 大小限制: 理论上Session的大小不受特定限制,但实际上受服务器资源的限制。
- 持久性: Session的生命周期在用户访问网站期间是持久的,但可能会受到服务器的配置和会话管理策略的影响。
- 跨域: Session存储在服务器端,因此可以在同一域名下的不同页面之间共享。
- 安全性: 相对于Cookie,Session的安全性更高,因为存储在服务器端,用户无法直接访问和修改Session数据。
区别总结:
- Cookie存储在客户端,Session存储在服务器端。
- Cookie有大小限制,Session理论上没有固定大小限制。
- Cookie可以在客户端持久存储,Session通常在用户关闭浏览器后失效。
- Cookie可以跨域共享,Session在同一域名下共享。
- Cookie的内容可以被用户修改,Session相对更安全。
TCP篇
什么是 TCP 连接
用于保证可靠性和流量控制维护的某些状态信息,这些信息的组合,包括 Socket、序列号和窗口大小称为连接。
UDP 和 TCP 有什么区别呢?分别的应用场景是?
1. 连接
- TCP 是面向连接的传输层协议,传输数据前先要建立连接。
- UDP 是不需要连接,即刻传输数据。
2. 服务对象
- TCP 是一对一的两点服务,即一条连接只有两个端点。
- UDP 支持一对一、一对多、多对多的交互通信
3. 可靠性
- TCP 是可靠交付数据的,数据可以无差错、不丢失、不重复、按序到达。
- UDP 是尽最大努力交付,不保证可靠交付数据。但是我们可以基于 UDP 传输协议实现一个可靠的传输协议,比如 QUIC 协议,具体可以参见这篇文章:如何基于 UDP 协议实现可靠传输?(opens new window)
4. 拥塞控制、流量控制
- TCP 有拥塞控制和流量控制机制,保证数据传输的安全性。
- UDP 则没有,即使网络非常拥堵了,也不会影响 UDP 的发送速率。
5. 首部开销
- TCP 首部长度较长,会有一定的开销,首部在没有使用「选项」字段时是
20个字节,如果使用了「选项」字段则会变长的。 - UDP 首部只有 8 个字节,并且是固定不变的,开销较小。
6. 传输方式
TCP 是流式传输,没有边界,但保证顺序和可靠。
UDP 是一个包一个包的发送,是有边界的,但可能会丢包和乱序。
TCP 和 UDP 应用场景:
由于 TCP 是面向连接,能保证数据的可靠性交付,因此经常用于:
FTP文件传输;- HTTP / HTTPS;
由于 UDP 面向无连接,它可以随时发送数据,再加上 UDP 本身的处理既简单又高效,因此经常用于:
- 包总量较少的通信,如
DNS、SNMP等; - 视频、音频等多媒体通信;
- 广播通信;
TCP 和 UDP 可以使用同一个端口吗?
可以;传输层的「端口号」的作用,是为了区分同一个主机上不同应用程序的数据包;传输层的两个传输协议 TCP 和 UDP,在内核中是两个完全独立的软件模块。
当主机收到数据包后,可以在 IP 包头的「协议号」字段知道该数据包是 TCP/UDP,所以可以根据这个信息确定送给哪个模块(TCP/UDP)处理,送给 TCP/UDP 模块的报文根据「端口号」确定送给哪个应用程序处理。
TCP三次握手与四次挥手
三次握手:
- 一开始,客户端和服务端都处于
CLOSE状态。先是服务端主动监听某个端口,处于LISTEN状态 - 第一次握手:客户端会随机初始化序号(
client_isn),同时把SYN标志位置为1,表示SYN报文。接着把第一个 SYN 报文发送给服务端,表示向服务端发起连接,之后客户端处于SYN-SENT状态; - 第二次握手:服务端收到客户端的 SYN 报文后,首先服务端也随机初始化自己的序号(server_isn),将此序号填入 TCP 首部的「序号」字段中,其次把 TCP 首部的「确认应答号」字段填入 client_isn + 1, 接着把 SYN 和 ACK 标志位置为 1。最后把该报文发给客户端,该报文也不包含应用层数据,之后服务端处于 SYN-RCVD 状态
- 第三次握手:客户端收到服务端报文后,还要向服务端回应最后一个应答报文,首先该应答报文 TCP 首部 ACK 标志位置为 1 ,其次「确认应答号」字段填入 server_isn + 1 ,最后把报文发送给服务端,这次报文可以携带客户到服务端的数据,之后客户端处于 ESTABLISHED 状态。
原因:
三次握手才可以阻止重复历史连接的初始化(主要原因);
如果是两次握手连接,就无法阻止历史连接,在两次握手的情况下,服务端在收到 SYN 报文后,就进入ESTABLISHED 状态,意味着这时可以给对方发送数据,但是客户端此时还没有进入 ESTABLISHED 状态,假设这次是历史连接,客户端判断到此次连接为历史连接,那么就会回 RST 报文来断开连接,而服务端在第一次握手的时候就进入 ESTABLISHED 状态,所以它可以发送数据的,但是它并不知道这个是历史连接,它只有在收到 RST 报文后,才会断开连接
三次握手才可以同步双方的初始序列号,如果只有两次握手只保证了一方的初始序列号能被对方成功接收,四次握手是将三次握手的第二次握手拆分为两次,第一次把ACK 置1,同时确认应答号为客户端初始序号+1,第二次把SYN置1,同时初始化自己的序号;
如果没有第三次握手,服务端不清楚客户端是否收到了自己回复的
ACK报文,所以服务端每收到一个SYN就只能先主动建立一个连接,当客户端发送的SYN报文在网络中阻塞了,重复发送多次SYN报文,那么服务端在收到请求后就会建立多个冗余的无效链接,造成不必要的资源浪费。
四次挥手
客户端发送FIN请求关闭TCP连接报文,客户端进入
FIN_WAIT_1状态;服务端收到该报文后,就向客户端发送
ACK应答报文,接着服务端进入CLOSE_WAIT状态。客户端收到服务端的
ACK应答报文后,之后进入FIN_WAIT_2状态。等待服务端处理完数据后,也向客户端发送
FIN报文,之后服务端进入LAST_ACK状态。客户端收到服务端的
FIN报文后,回一个ACK应答报文,之后进入TIME_WAIT状态服务端收到了
ACK应答报文后,就进入了CLOSE状态,至此服务端已经完成连接的关闭。客户端在经过
2MSL一段时间后,自动进入CLOSE状态,至此客户端也完成连接的关闭。
第三次握手丢失了,会发生什么?
因为这个第三次握手的 ACK 是对第二次握手的 SYN 的确认报文,所以当第三次握手丢失了,如果服务端那一方迟迟收不到这个确认报文,就会触发超时重传机制,重传 SYN-ACK 报文,直到收到第三次握手,或者达到最大重传次数。注意,ACK 报文是不会有重传的,当 ACK 丢失了,就由对方重传对应的报文。
为什么需要 TIME_WAIT 状态?
发送FIN只是表示关闭了发送数据,在进入CLOSE状态前依然可以接收数据;
需要 TIME-WAIT 状态,主要是两个原因:
- 防止历史连接中的数据,被后面相同四元组的连接错误的接收;
- 保证「被动关闭连接」的一方,能被正确的关闭,优雅关闭TCP连接;
客户端必须等待足够长的时间,确保服务端能够收到 ACK,如果服务端没有收到 ACK,那么就会触发 TCP 重传机制,服务端会重新发送一个 FIN,这样一去一来刚好两个 MSL 的时间。客户端在收到服务端重传的 FIN 报文时,TIME_WAIT 状态的等待时间,会重置回 2MSL。
这2个MSL中的第一个MSL是为了等自己发出去的最后一个ACK从网络中消失,而第二MSL是为了等在对端收到ACK之前的一刹那可能重传的FIN报文从网络中消失
假设客户端没有 TIME_WAIT 状态,而是在发完最后一次回 ACK 报文就直接进入 CLOSE 状态,如果该 ACK 报文丢失了,服务端则重传的 FIN 报文,而这时客户端已经进入到关闭状态了,在收到服务端重传的 FIN 报文后,就会回 RST 报文。
服务端收到这个 RST 并将其解释为一个错误(Connection reset by peer),这对于一个可靠的协议来说不是一个优雅的终止方式。
为什么 TIME_WAIT 等待的时间是 2MSL?
TIME_WAIT 等待 2 倍的 MSL,比较合理的解释是: 网络中可能存在来自发送方的数据包,当这些发送方的数据包被接收方处理后又会向对方发送响应,所以一来一回需要等待 2 倍的时间。
比如,如果被动关闭方没有收到断开连接的最后的 ACK 报文,就会触发超时重发 FIN 报文,另一方接收到 FIN 后,会重发 ACK 给被动关闭方, 一来一去正好 2 个 MSL。
客户端调用 close 了,连接是断开的流程是什么?

- 客户端调用
close,表明客户端没有数据需要发送了,则此时会向服务端发送 FIN 报文,进入 FIN_WAIT_1 状态; - 服务端接收到了 FIN 报文,TCP 协议栈会为 FIN 包插入一个文件结束符
EOF到接收缓冲区中,应用程序可以通过read调用来感知这个 FIN 包。这个EOF会被放在已排队等候的其他已接收的数据之后,这就意味着服务端需要处理这种异常情况,因为 EOF 表示在该连接上再无额外数据到达。此时,服务端进入 CLOSE_WAIT 状态; - 当处理完数据后,自然就会读到
EOF,于是也调用close关闭它的套接字,这会使得服务端发出一个 FIN 包,之后处于 LAST_ACK 状态; - 客户端接收到服务端的 FIN 包,并发送 ACK 确认包给服务端,此时客户端将进入 TIME_WAIT 状态;
服务端收到 ACK 确认包后,就进入了最后的 CLOSE 状态;
客户端经过 2MSL 时间之后,也进入 CLOSE 状态;
服务器出现大量 CLOSE_WAIT 状态的原因有哪些?
CLOSE_WAIT 状态是「被动关闭方」才会有的状态,而且如果「被动关闭方」没有调用 close 函数关闭连接,那么就无法发出 FIN 报文,从而无法使得 CLOSE_WAIT 状态的连接转变为 LAST_ACK 状态。
所以,当服务端出现大量 CLOSE_WAIT 状态的连接的时候,说明服务端的程序没有调用 close 函数关闭连接。
如果已经建立了连接,但是客户端突然出现故障了怎么办?
客户端出现故障指的是客户端的主机发生了宕机,或者断电的场景。发生这种情况的时候,如果服务端一直不会发送数据给客户端,那么服务端是永远无法感知到客户端宕机这个事件的,也就是服务端的 TCP 连接将一直处于 ESTABLISH 状态,占用着系统资源。
为了避免这种情况,TCP 搞了个保活机制:每隔一个时间间隔,发送一个探测报文,该探测报文包含的数据非常少,如果连续几个探测报文都没有得到响应,则认为当前的 TCP 连接已经死亡,系统内核将错误信息通知给上层应用程序。
TCP 保活的这个机制检测的时间是有点长,可以在应用层实现一个心跳机制:
web 服务软件一般都会提供 keepalive_timeout 参数,用来指定 HTTP 长连接的超时时间。如果设置了 HTTP 长连接的超时时间是 60 秒,web 服务软件就会启动一个定时器,如果客户端在完成一个 HTTP 请求后,在 60 秒内都没有再发起新的请求,定时器的时间一到,就会触发回调函数来释放该连接。
如果已经建立了连接,但是服务端的进程崩溃会发生什么?
TCP 的连接信息是由内核维护的,所以当服务端的进程崩溃后,内核需要回收该进程的所有 TCP 连接资源,于是内核会发送第一次挥手 FIN 报文,后续的挥手过程也都是在内核完成,并不需要进程的参与,所以即使服务端的进程退出了,还是能与客户端完成 TCP 四次挥手的过程。
TCP重传机制
超时重传:就是在发送数据时,设定一个定时器,当超过指定的时间后,没有收到对方的
ACK确认应答报文,就会重发该数据,也就是我们常说的超时重传快速重传:工作方式是当收到三个相同的 ACK 报文时,会在定时器过期之前,重传丢失的报文段。
SACK 方法(Selective Acknowledgment 号选择性确认):可以知道哪些数据收到了,哪些数据没收到,知道了这些信息,就可以只重传丢失的数据。
Duplicate SACK:其主要使用了 SACK 来告诉「发送方」有哪些数据被重复接收了。,能够检测ACK丢包情况、网络延迟情况
TCP粘包是什么? 为什么UDP不粘包?IP 层有粘包问题吗?
应用层传到 TCP 协议的数据,不是以消息报为单位向目的主机发送,而是以字节流的方式发送到下游,这些数据可能被切割和组装成各种数据包,接收端收到这些数据包后没有正确还原原来的消息,因此出现粘包现象。
出现粘包的原因
出现粘包的原因是多方面的,可能是来自发送方,也可能是来自接收方。
发送方原因 :TCP默认使用Nagle算法
Nagle算法主要做两件事:
- 只有上一个分组得到确认,才会发送下一个分组
- 收集多个小分组,在一个确认到来时一起发送
接收方原因
TCP接收到数据包时,并不会马上交到应用层进行处理,会将接收到的数据包保存在接收缓存里,然后应用程序主动从缓存读取收到的分组。这样一来,如果TCP接收数据包到缓存的速度大于应用程序从缓存中读取数据包的速度,多个包就会被缓存,应用程序就有可能读取到多个首尾相接粘到一起的包。
如何解决粘包
粘包的问题出现是因为不知道一个用户消息的边界在哪,如果知道了边界在哪,接收方就可以通过边界来划分出有效的用户消息。一般有三种方式分包的方式:
固定长度的消息;即每个用户消息都是固定长度的,比如规定一个消息的长度是 64 个字节,当接收方接满 64 个字节,就认为这个内容是一个完整且有效的消息。
特殊字符作为边界;消息之间插入一个特殊的字符串,这样接收方在接收数据时,读到了这个特殊字符,就把认为已经读完一个完整的消息。HTTP 通过设置回车符、换行符作为 HTTP 报文协议的边界。
自定义消息结构;消息结构,由包头和数据组成,其中包头包是固定大小的,而且包头里有一个字段来说明紧随其后的数据有多大。当接收方接收到包头的大小(比如 4 个字节)后,就解析包头的内容,于是就可以知道数据的长度,然后接下来就继续读取数据,直到读满数据的长度,就可以组装成一个完整到用户消息来处理了。
UDP不沾包
TCP为了保证可靠传输并减少额外的开销(每次发包都要验证),采用了基于流的传输,基于流的传输不认为消息是一条一条的,是无保护消息边界的(保护消息边界:指传输协议把数据当做一条独立的消息在网上传输,接收端一次只能接受一条独立的消息)。
UDP是面向无连接,不可靠的,基于数据报的传输层通信协议,是有保护消息边界的,接收方一次只接受一条独立的信息,所以不存在粘包问题。
IP 层有粘包问题吗
IP 层从按长度切片到把切片组装成一个数据包的过程中,都只管运输,都不需要在意消息的边界和内容,都不在意消息内容了,那就不会有粘包一说了;
数据包也只是按着 TCP 的方式进行组装和拆分,如果数据包有错,那数据包也只是犯了每个数据包都会犯的错而已。
ssh的公钥与私钥的作用
非对称密钥密码系统,每个通信方均需要两个密钥,即公钥和私钥,这两把密钥可以互为加解密。公钥是公开的,不需要保密,而私钥是由个人自己持有;非对称密钥密码的主要应用就是公钥加密和公钥认证;
公钥加密
Alice想把一段明文通过双钥加密的技术发送给Bob,Bob有一对公钥和私钥,那么加密解密的过程如下:
- Bob将他的公开密钥传送给Alice。
- Alice用Bob的公开密钥加密她的消息,然后传送给Bob。
- Bob用他的私人密钥解密Alice的消息。
公钥认证
主要用户鉴别用户的真伪,Alice想让Bob知道自己是真实的Alice,而不是假冒的;
- Alice用她的私人密钥对文件加密,从而对文件签名。
- Alice将签名的文件传送给Bob。
- Bob用Alice的公钥解密文件,从而验证签名。
SSH提供公钥登录
用户将自己的公钥储存在远程主机上。登录的时候,远程主机会向用户发送一段随机字符串,用户用自己的私钥加密后,再发回来。远程主机用事先储存的公钥进行解密,如果成功,就证明用户是可信的,直接允许登录;
怎么判断网络拥塞?
判断网络拥塞可以通过以下几种方法:
- 延迟增加:当网络出现拥塞时,数据包在传输过程中会遇到更多的延迟。因此,监测数据包的往返时间(Round-Trip Time,RTT)或数据包的传输延迟可以用来判断网络拥塞情况。如果延迟明显增加,可能表示网络发生了拥塞。
- 丢包率增加:网络拥塞时,路由器或交换机可能丢弃部分数据包,导致数据包丢失。监测数据包的丢失率可以判断网络是否发生拥塞。丢包率的增加通常会导致数据传输的性能下降。
- 带宽利用率:当网络发生拥塞时,网络带宽可能被完全占用,导致带宽利用率接近100%。监测带宽利用率可以判断网络是否处于拥塞状态。
- TCP拥塞窗口:TCP协议中有一个拥塞窗口(Congestion Window),它表示在任意时刻发送方能够发送的最大数据量。在网络拥塞时,TCP拥塞窗口可能会减小,从而限制了数据的传输速率。
- 流量分析:通过对网络流量进行分析,可以检测是否有大量的数据包在网络中堆积,从而判断是否发生了拥塞。
以上方法可以结合使用,以综合判断网络是否发生了拥塞。在实际应用中,可以通过网络监测工具、网络分析工具等来实时监测和诊断网络状态,从而及时发现并解决网络拥塞问题。
如何理解TCP滑动窗口与拥塞控制
滑动窗口
背景:TCP 是每发送一个数据,都要进行一次确认应答,一问一答的情况下,数据包的往返时间越长,通信的效率就越低。
窗口的实现实际上是操作系统开辟的一个缓存空间,发送方主机在等到确认应答返回之前,必须在缓冲区中保留已发送的数据。如果按期收到确认应答,此时数据就可以从缓存区清除。
窗口大小就是指无需等待确认应答,而可以继续发送数据的最大
窗口大小由哪一方决定?
TCP 头里有一个字段叫 Window,也就是窗口大小。
这个字段是接收端告诉发送端自己还有多少缓冲区可以接收数据。于是发送端就可以根据这个接收端的处理能力来发送数据,而不会导致接收端处理不过来。
所以,通常窗口的大小是由接收方的窗口大小来决定的。
发送方发送的数据大小不能超过接收方的窗口大小,否则接收方就无法正常接收到数据。

接收窗口和发送窗口的大小是相等的吗?
接收窗口的大小是约等于发送窗口的大小的。
因为滑动窗口并不是一成不变的。比如,当接收方的应用进程读取数据的速度非常快的话,这样的话接收窗口可以很快的就空缺出来。那么新的接收窗口大小,是通过 TCP 报文中的 Windows 字段来告诉发送方。那么这个传输过程是存在时延的,所以接收窗口和发送窗口是约等于的关系。
流量控制
TCP 提供一种机制可以让「发送方」根据「接收方」的实际接收能力控制发送的数据量,这就是所谓的流量控制。
TCP 是如何解决窗口关闭时,潜在的死锁现象呢?
当发生窗口关闭时,接收方处理完数据后,会向发送方通告一个窗口非 0 的 ACK 报文,如果这个通告窗口的 ACK 报文在网络中丢失了,这会导致发送方一直等待接收方的非 0 窗口通知,接收方也一直等待发送方的数据,如不采取措施,这种相互等待的过程,会造成了死锁的现象。
如果持续计时器超时,就会发送窗口探测 ( Window probe ) 报文,而对方在确认这个探测报文时,给出自己现在的接收窗口大小。
拥塞控制
控制的目的就是避免「发送方」的数据填满整个网络。当网络拥堵时会发送数据包时延、丢失等情况,这时 TCP 就会重传数据,进一步恶性循环加重网络拥堵。
拥塞控制就是在「发送方」调节所要发送数据的量,避免「发送方」的数据填满整个网络。
拥塞窗口 cwnd是发送方维护的一个的状态变量,它会根据网络的拥塞程度动态变化的,发送窗口的值是swnd = min(cwnd, rwnd),也就是拥塞窗口和接收窗口中的最小值。
拥塞窗口 cwnd 变化的规则:
- 只要网络中没有出现拥塞,
cwnd就会增大; - 但网络中出现了拥塞,
cwnd就减少;
那么怎么知道当前网络是否出现了拥塞呢?
其实只要「发送方」没有在规定时间内接收到 ACK 应答报文,也就是发生了超时重传,就会认为网络出现了拥塞。
拥塞控制有哪些控制算法?
拥塞控制主要是四个算法:
- 慢启动
- 拥塞避免
- 拥塞发生
- 快速恢复
慢启动算法:TCP 在刚建立连接完成后,首先是有个慢启动的过程,这个慢启动的意思就是一点一点的提高发送数据包的数量(指数型增长);
拥塞避免算法:当拥塞窗口 cwnd 「超过」慢启动门限 ssthresh 就会进入拥塞避免算法。它的规则是:**每当收到一个 ACK 时,cwnd 增加 1/cwnd(线性增长);
拥塞发生:cwnd = cwnd/2 ,也就是设置为原来的一半;慢启动门限ssthresh = cwnd;
快速恢复:拥塞窗口 cwnd = ssthresh + 3
TCP拥塞控制(Congestion Control)和流量控制(Flow Control)
是两个不同但相关的概念,用于管理数据在计算机网络中的传输。它们的主要区别在于它们所处理的问题和目标。
TCP拥塞控制(Congestion Control):
目标:TCP拥塞控制的主要目标是确保网络中没有过多的数据包丢失或堵塞,以维持网络的稳定性和性能。它旨在防止网络拥塞,以确保所有参与通信的设备都能够公平共享网络资源,并在出现拥塞时降低传输速率,以减少数据包丢失。
控制机制:TCP拥塞控制使用一系列算法和技术来检测网络拥塞的迹象,并采取措施来减少发送到网络中的数据量。这包括慢启动、拥塞避免、拥塞检测等算法。TCP通过调整发送速率来响应网络拥塞,从而减少拥塞并恢复网络性能。
运行范围:TCP拥塞控制是端到端的,它关注的是整个网络路径上的拥塞情况,而不仅仅是两个通信节点之间的数据传输。
流量控制(Flow Control):
目标:
流量控制的主要目标是确保发送方不会以过快的速度向接收方发送数据,以防止接收方无法处理太多数据而导致数据丢失或溢出。流量控制主要关注通信端点之间的数据流速率匹配。控制机制:流量控制通常在数据传输的端点之间进行,涉及发送方和接收方之间的协商。通常使用滑动窗口大小(Window Size)来控制数据的流动速率。接收方通过告知发送方其可接受的数据窗口大小,发送方根据这个窗口大小来限制发送的数据量。
运行范围:流量控制是端点之间的问题,主要由发送方和接收方之间的协商来控制数据流速率,而不涉及整个网络路径上的拥塞。
总结来说,TCP拥塞控制关注整个网络路径上的拥塞情况,目标是维护网络的稳定性和性能,而流量控制主要关注通信端点之间的数据流速率匹配,以确保接收方能够处理数据的速率。这两个机制都是为了提高网络性能和可靠性,但它们解决不同层次和类型的问题。
TCP如何保证可靠的连接
TCP(传输控制协议)通过一系列的机制来保证可靠的连接:
- 确认和重传:TCP使用确认机制,接收方会对收到的数据进行确认应答,如果发送方在合理的时间内未收到确认应答,就会认为数据丢失或损坏,触发数据的重传。这样可以确保数据的可靠传输。
- 序列号和窗口:TCP通过序列号对数据进行编号,接收方根据序列号将乱序的数据重新组装成正确的顺序。同时,TCP还使用滑动窗口机制来控制发送方发送数据的速率,确保接收方能够及时处理数据。
- 连接建立和终止:TCP在建立连接时使用三次握手,确保双方都能够正确收发数据。在连接终止时使用四次挥手,确保双方都知道连接已经关闭。
- 流量控制:TCP使用滑动窗口来控制发送方发送数据的速率,确保接收方能够及时处理数据,避免数据的积压和丢失。
- 拥塞控制:TCP使用拥塞控制算法来调整发送速率,以避免网络拥塞和数据包丢失。拥塞控制通过动态调整拥塞窗口大小来实现。
- 超时重传:如果发送方发送的数据在合理的时间内未收到确认应答,就会触发超时重传,重新发送数据,确保数据的可靠传输。
通过这些机制,TCP能够在不可靠的IP网络上提供可靠的连接。当网络条件发生变化时,TCP会根据具体情况动态调整自身的行为,以保证数据的可靠传输和连接的稳定性。
UDP连接为什么是不可靠的
UDP(用户数据报协议)连接是不可靠的,主要有以下几个原因:
- 无连接:UDP是一种面向无连接的协议,发送数据前不需要建立连接,也不需要维护连接状态。因此,没有握手和挥手过程,连接的建立和释放都比较简单。但同时也意味着在传输过程中,不会对数据包进行确认和重传,也不会保证数据包的顺序。
- 不保证可靠性:UDP不对数据传输的可靠性进行保证。如果在传输过程中发生数据包的丢失、重复、损坏或乱序,UDP不会进行任何处理,而是直接将数据交给上层应用程序处理。这使得UDP传输速度较快,但也导致了不可靠性。
- 不支持拥塞控制:TCP使用拥塞控制算法来调整发送速率,以避免网络拥塞和数据包丢失。而UDP不支持拥塞控制,发送方会连续发送数据,无论网络的拥塞情况如何,容易导致网络拥塞,进而导致数据丢失。
- 无法保证顺序:UDP发送的数据包在网络中可能经过不同的路径到达目的地,因此数据包的顺序可能会发生变化。而TCP会对数据包进行排序,保证数据包按顺序传输。
因为这些特点,UDP适用于一些对数据传输速度要求较高,但对数据可靠性和顺序要求不高的场景,比如视频直播、实时游戏等。而对于对数据传输的可靠性和顺序要求较高的场景,一般使用TCP连接。
既然 IP 层会分片,为什么 TCP 层还需要 MSS 呢?
MTU:一个网络包的最大长度,以太网中一般为1500字节;MSS:除去 IP 和 TCP 头部之后,一个网络包所能容纳的 TCP 数据的最大长度;
IP 分片是指在网络通信中,当一个 IP 数据包的大小超过网络传输链路的 MTU(Maximum Transmission Unit),将会被拆分成多个较小的 IP 分片进行传输。
存在隐患:当如果一个 IP 分片丢失,整个 IP 报文的所有分片都得重传。因为 IP 层本身没有超时重传机制,它由传输层的 TCP 来负责超时和重传。
当某一个 IP 分片丢失后,接收方的 IP 层就无法组装成一个完整的 TCP 报文(头部 + 数据),也就无法将数据报文送到 TCP 层,所以接收方不会响应 ACK 给发送方,因为发送方迟迟收不到 ACK 确认报文,所以会触发超时重传,就会重发「整个 TCP 报文(头部 + 数据)」。
因此,尽量避免 IP 分片,由 IP 层进行分片传输,是非常没有效率的;
为了达到最佳的传输效能 TCP 协议在建立连接的时候通常要协商双方的 MSS 值,当 TCP 层发现数据超过 MSS 时,则就先会进行分片,当然由它形成的 IP 包的长度也就不会大于 MTU ,自然也就不用 IP 分片了。
经过 TCP 层分片后,如果一个 TCP 分片丢失后,进行重发时也是以 MSS 为单位,而不用重传所有的分片,大大增加了重传的效率。
Git分支管理
https://zhuanlan.zhihu.com/p/38772378
https://blog.csdn.net/silence_pinot/article/details/111478596
1 | 查看分支列表: git branch |
TCP 半连接队列和全连接队列?
在 TCP 三次握手的时候,Linux 内核会维护两个队列,分别是:
半连接队列,也称 SYN 队列;全连接队列,也称 accept 队列;
服务端收到客户端发起的 SYN 请求后,内核会把该连接存储到半连接队列,并向客户端响应 SYN+ACK,接着客户端会返回 ACK,服务端收到第三次握手的 ACK 后,内核会把连接从半连接队列移除,然后创建新的完全的连接,并将其添加到 accept 队列,等待进程调用 accept 函数时把连接取出来。
如何优化 TCP?
三次握手的性能优化
客户端优化:根据网络的稳定性和目标服务器的繁忙程度修改 SYN 的重传次数,调整客户端的三次握手时间上限。比如内网中通讯时,就可以适当调低重试次数,尽快把错误暴露给应用程序。
服务端优化:Linux 内核会建立一个「半连接队列」来维护「未完成」的握手信息,当半连接队列溢出后,服务端就无法再建立新的连接。
服务器收到 ACK 后连接建立成功,此时,内核会把连接从半连接队列移除,然后创建新的完全的连接,并将其添加到 accept 队列,等待进程调用 accept 函数时把连接取出来。如果进程不能及时地调用 accept 函数,就会造成 accept 队列(也称全连接队列)溢出,最终导致建立好的 TCP 连接被丢弃。绕过三次握手:三次握手建立连接造成的后果就是,HTTP 请求必须在一个 RTT(从客户端到服务器一个往返的时间)后才能发送。

在 Linux 3.7 内核版本之后,提供了 TCP Fast Open 功能,这个功能可以减少 TCP 连接建立的时延。
四次挥手的性能优化
当进程调用了 close 函数关闭连接,此时连接就会是「孤儿连接」,因为它无法再发送和接收数据。
Linux 系统为了防止孤儿连接过多,导致系统资源长时间被占用,就提供了 tcp_max_orphans 参数。如果孤儿连接数量大于它,新增的孤儿连接将不再走四次挥手,而是直接发送 RST 复位报文强制关闭。

数据传输的性能提升
TCP 连接是由内核维护的,内核会为每个连接建立内存缓冲区:
通过滑动窗口进行流量控制,进而影响传输速度;
接收方根据它的缓冲区,可以计算出后续能够接收多少字节的报文,这个数字叫做接收窗口。当内核接收到报文时,必须用缓冲区存放它们,这样剩余缓冲区空间变小,接收窗口也就变小了;当进程调用 read 函数后,数据被读入了用户空间,内核缓冲区就被清空,这意味着主机可以接收更多的报文,接收窗口就会变大。
如何理解是 TCP 面向字节流协议?
UDP 是面向数据报文的协议
当用户消息通过 UDP 协议传输时,操作系统不会对消息进行拆分,在组装好 UDP 头部后就交给网络层来处理,所以发出去的 UDP 报文中的数据部分就是完整的用户消息,也就是每个 UDP 报文就是一个用户消息的边界,这样接收方在接收到 UDP 报文后,读一个 UDP 报文就能读取到完整的用户消息。
操作系统在收到 UDP 报文后,会将其插入到队列里,队列里的每一个元素就是一个 UDP 报文,这样当用户调用 recvfrom() 系统调用读数据的时候,就会从队列里取出一个数据,然后从内核里拷贝给用户缓冲区。
TCP 是面向字节流的协议
当用户消息通过 TCP 协议传输时,消息可能会被操作系统分组成多个的 TCP 报文,也就是一个完整的用户消息被拆分成多个 TCP 报文进行传输,这些消息报文是无保护消息边界的,这样的传输也被看成是流式的传输。
粘包问题
在HTTP请求中,请求头和请求体之间是通过一个空行(\r\n\r\n)来分隔的。因此,在处理HTTP请求时,请求头和请求体之间不会出现粘包问题。服务器会根据请求头中的Content-Length字段或Transfer-Encoding字段来确定请求体的长度,从而正确读取请求体的数据。
粘包问题通常在TCP层面出现,由于TCP是一个字节流协议,因此多个数据包可能会被合并在一起,从而导致粘包现象。但在HTTP层面,由于有请求头和请求体之间的分隔标志,服务器可以正确地识别并处理每个HTTP请求。
已建立连接的TCP,收到SYN会发生什么?
一个已经建立的 TCP 连接,客户端中途宕机了,而服务端此时也没有数据要发送,一直处于 Established 状态,客户端恢复后,向服务端建立连接,此时服务端会怎么处理?
1. 客户端的 SYN 报文里的端口号与历史连接不相同
如果客户端恢复后发送的 SYN 报文中的源端口号跟上一次连接的源端口号不一样,此时服务端会认为是新的连接要建立,于是就会通过三次握手来建立新的连接。
那旧连接里处于 Established 状态的服务端最后会怎么样呢?
如果服务端发送了数据包给客户端,由于客户端的连接已经被关闭了,此时客户的内核就会回 RST 报文,服务端收到后就会释放连接。
如果服务端一直没有发送数据包给客户端,在超过一段时间后,TCP 保活机制就会启动,检测到客户端没有存活后,接着服务端就会释放掉该连接。
2. 客户端的 SYN 报文里的端口号与历史连接相同

处于 Established 状态的服务端,如果收到了客户端的 SYN 报文(注意此时的 SYN 报文其实是乱序的,因为 SYN 报文的初始化序列号其实是一个随机数),会回复一个携带了正确序列号和确认号的 ACK 报文,这个 ACK 被称之为 Challenge ACK。
接着,客户端收到这个 Challenge ACK,发现确认号(ack num)并不是自己期望收到的,于是就会回 RST 报文,服务端收到后,就会释放掉该连接。
IP篇
常见IP相关计算
网络号:将IP地址的二进制和子网掩码的二进制进行“&”(and)运算;
广播地址:将网络号右边的表示IP地址的主机部分的二进制位全部填上1,再将得到的二进制数转换为十进制数就可以得到广播地址;
可用IP地址范围:因为网络号是172.31.128.0,广播地址是172.31.191.255,所以子网中可用的IP地址范围就是从网络号+1 ~广播地址-1,所以子网中的可用IP地址范围就是从172.31.128.1-172.31.191.254。
主机数计算:2的Y次方-2(Y是子网掩码中0的个数)-2是掐头去尾,头是网络号,尾是广播地址;
子网数目:2的X次方(X是子网掩码中,借的1的个数)B类掩码默类是用16位,这里的掩码在B类默认掩码的基础上多出了两个表示网络号的1,也就是向主机位借了两个1;
1 | IP地址和子网掩码 172.31.128.255 / 18 |
1 | IP地址块为211.168.15.192/26、211.168.15.160/27和211.168.15.128/27三个地址块经聚合后可用地址数为(A) |
1 | 如果将网络IP段40.15.128.0/17划分成2个子网,则第一个子网IP段为40.15.128.0/18,则第二个子网为:(D) |
1 | 对于IP地址130.63.160.2,MASK为255.255.255.0,子网号为(B) |
三、操作系统
硬件结构
CPU 是如何执行程序的?
冯诺依曼模型
定义计算机基本结构为 5 个部分,分别是运算器、控制器、存储器、输入设备、输出设备
线路位宽与 CPU 位宽
地址总线的位宽度是指 CPU 同时传输地址信息的线路数量。例如,32 位的地址总线具有 32 条传输地址信息的线路,64 位的地址总线具有 64 条传输地址信息的线路。
CPU 操作 4G 大的内存,那么就需要 32 条地址总线,因为
2 ^ 32 = 4G。
计算机可以寻址 $2^{32}$ 个不同的内存单元。而每个内存单元的大小是一个字节,这是因为在计算机中,信息被存储在内存中的最小单位就是一个字节。
16GB内存的计算机使用“GB”(GigaByte,即千兆字节)作为单位来表示内存容量大小。16GB表示这台计算机的内存容量是16个GB,即1610241024*1024字节。
而CPU操作4G大的内存时,需要32条地址总线,是因为4G字节的内存需要32个二进制位(32个比特)来表示内存地址。因此,32条地址总线可以支持寻址$2^{32}$个不同的内存地址,每个地址对应一个字节,从而可以操作4GB大小的内存。
因此,16GB内存的计算机和CPU操作4G大的内存所需要的地址总线数量之间存在一定的联系,但它们是描述内存容量大小的不同方式。可以这样理解:16GB内存的计算机可以容纳比4GB内存的计算机更多的数据,但在CPU访问这些数据时,都需要通过内存地址来定位,而内存地址的位数和地址总线的数量都是限制CPU访问的内存大小的因素。
程序执行的时候,CPU 会根据程序计数器里的内存地址,从内存里面把需要执行的指令读取到指令寄存器里面执行,然后根据指令长度自增,开始顺序读取下一条指令。
64 位相比 32 位 CPU 的优势在哪吗?64 位 CPU 的计算性能一定比 32 位 CPU 高很多吗?
你知道软件的 32 位和 64 位之间的区别吗?再来 32 位的操作系统可以运行在 64 位的电脑上吗?64 位的操作系统可以运行在 32 位的电脑上吗?如果不行,原因是什么?
- 硬件的 64 位和 32 位指的是 CPU 的位宽,软件的 64 位和 32 位指的是程序指令的位宽
- 如果 32 位指令在 64 位机器上执行,需要一套兼容机制,就可以做到兼容运行了。但是如果 64 位指令在 32 位机器上执行,就比较困难了,因为 32 位的寄存器存不下 64 位的指令;
Cache是干什么的?Cache基于什么?为什么要设置多级Cache?
Cache是一种高速缓存,用于存储和提供快速访问数据的副本,以加速计算机系统的性能。它位于计算机系统的主存(RAM)和中央处理器(CPU)之间,用于解决CPU访问主存速度较慢的问题。
Cache基于局部性原理,即在程序执行期间,存在较高的数据和指令的重复访问模式。Cache利用这种局部性原理,将最常用的数据和指令存储在更快的存储介质中,以便在需要时能够更快地访问它们。
设置多级Cache是为了更好地利用局部性原理和逐级加速访问的特性。通常,计算机系统会采用多级Cache结构,包括L1、L2、L3等不同级别的Cache。这些级别的Cache之间以及与主存之间有不同的访问速度和容量。
L1 Cache是最接近CPU的缓存,速度最快但容量最小。L2 Cache位于L1 Cache和主存之间,速度较慢但容量较大。L3 Cache是更高级别的缓存,位于L2 Cache和主存之间。设置多级Cache可以利用不同级别Cache之间的速度和容量差异,以及局部性原理,提供更高效的数据访问,减少CPU访问主存的次数,从而提高计算机系统的整体性能。
如何写出让 CPU 跑得更快的代码?
要想写出让 CPU 跑得更快的代码,就需要写出缓存命中率高的代码,CPU L1 Cache 分为数据缓存和指令缓存,因而需要分别提高它们的缓存命中率:
- 对于数据缓存,我们在遍历数据的时候,应该按照内存布局的顺序操作,这是因为 CPU Cache 是根据 CPU Cache Line 批量操作数据的,所以顺序地操作连续内存数据时,性能能得到有效的提升;
1 | 二维数组 |
- 对于指令缓存,有规律的条件分支语句能够让 CPU 的分支预测器发挥作用,进一步提高执行的效率;
1 | 第一个操作,循环遍历数组,把小于 50 的数组元素置为 0; |
另外,对于多核 CPU 系统,线程可能在不同 CPU 核心来回切换,这样各个核心的缓存命中率就会受到影响,于是要想提高线程的缓存命中率,可以考虑把线程绑定 CPU 到某一个 CPU 核心
进程和线程的区别
- 进程是系统资源分配的最小单位,线程是程序执行的最小单位。每个进程都有自己的独立地址空间,而线程共享进程的地址空间。
- 资源占用:每个进程都有自己独立的地址空间和系统资源(如文件描述符、网络连接),因此多个进程之间的资源是相互隔离的。而线程共享同一个进程的地址空间和系统资源,因此多个线程可以直接访问共享的数据,但是一个线程崩溃可能导致整个进程崩溃。
- 通信和同步:进程通信需要通过IPC机制,如管道、消息队列、信号量等,而线程可以通过共享内存等更简单的方式进行通信。
- 切换开销:由于每个进程都有独立的地址空间,进程间切换的开销比较大,需要切换页表和上下文。而线程在同一个进程内,切换开销较小,只需要切换线程的上下文
- 在多核CPU上,多个线程可以并行执行,从而提高程序的执行效率,而多个进程只能并发执行。
多进程适用的场景:
- 需要隔离资源,防止不同任务之间相互干扰或影响。
- 需要充分利用多核处理器,将计算任务分配给多个独立的进程并行执行。
- 需要高可靠性,即使一个进程崩溃,其他进程仍然可以继续运行。
多线程适用的场景:
- 需要共享数据和共享资源,多个线程可以直接访问相同的数据结构,减少数据传输和拷贝开销。
- 需要响应性,例如图形界面应用程序需要及时响应用户的操作,使用多线程可以保持界面的流畅性。
- 需要进行异步编程,处理IO密集型任务时可以通过多线程实现并发处理,提高效率。
协程(Coroutine)是一种轻量级的用户级线程,也被称为协作式多任务处理。与操作系统提供的线程不同,协程的调度和切换不需要进入内核态,而是由用户态的程序自己控制。因此,协程的切换速度非常快,可以避免上下文切换的开销,提高程序的并发能力。
在协程中,程序会在特定的位置暂停,并保留当前状态。下次执行时,程序会从上次暂停的位置继续执行,这个过程中不需要重新加载程序的上下文信息,因此可以实现非常高效的切换。协程通常由程序员自己管理,可以在程序中任意创建和销毁,没有像线程那样的资源消耗。
线程共享的资源:
- 内存空间:所有线程在同一进程内共享相同的代码段和数据段,这包括程序的指令、全局变量和静态变量等。
- 文件描述符:线程共享同一进程的文件描述符表,因此它们可以同时访问同一文件、套接字或其他文件系统资源。
- 堆内存:线程可以共享进程的堆内存,这意味着它们可以访问和修改堆中的数据结构和动态分配的内存。
- 全局变量:线程可以访问和修改全局变量,但需要注意在多线程环境中对全局变量进行同步以避免竞态条件。
线程独有的资源:
- 线程栈:每个线程都有自己的栈,用于存储局部变量和函数调用信息。线程之间的栈是独立的,因此不会互相干扰。
- 线程本地存储(Thread-Local Storage,TLS):线程可以拥有自己的线程本地存储,其中的数据对其他线程不可见。
- 线程控制块(Thread Control Block,TCB):每个线程都有自己的控制块,用于存储线程的状态信息、寄存器状态、线程标识等。
- 寄存器集合:线程拥有自己的寄存器集合,包括程序计数器、栈指针等。这使得线程可以在切换时保留自己的寄存器状态,从而实现线程切换。
进程通信的本质
每个进程各自有不同的用户地址空间,任何一个进程的全局变量在另一个进程中都看不到,所以进程之间要交换数据必须通过内核,在内核中开辟一块缓冲区,进程1把数据从用户空间拷到内核缓冲区,进程2再从内核缓冲区把数据读走,内核提供的这种机制称为进程间通信机制。
管道(pipe)
管道又名匿名管道,这是一种最基本的IPC机制,由pipe函数创建:
#include <unistd.h>
int pipe(int pipefd[2]);
返回值:成功返回0,失败返回-1;
调用pipe函数时在内核中开辟一块缓冲区用于通信,它有一个读端,一个写端:pipefd[0]指向管道的读端,pipefd[1]指向管道的写端。所以管道在用户程序看起来就像一个打开的文件,通过read(pipefd[0])或者write(pipefd[1])向这个文件读写数据,其实是在读写内核缓冲区。
1.父进程调用pipe开辟管道,得到两个文件描述符指向管道的两端。
2.父进程调用fork创建子进程,那么子进程也有两个文件描述符指向同一管道。
3.父进程关闭管道读端,子进程关闭管道写端。父进程可以往管道里写,子进程可以从管道里读,管道是用环形队列实现的,数据从写端流入从读端流出,这样就实现了进程间通信。
两个进程通过一个管道只能实现单向通信,如果想双向通信必须再重新创建一个管道或者使用sockpair才可以解决这类问题;只能用于具有亲缘关系的进程间通信,例如父子,兄弟进程。
命名管道FIFO
和匿名管道的主要区别在于,命名管道有一个名字,命名管道的名字对应于一个磁盘索引节点,有了这个文件名,任何进程有相应的权限都可以对它进行访问。它允许无亲缘关系进程间的通信;
而匿名管道却不同,进程只能访问自己或祖先创建的管道,而不能访任意访问已经存在的管道——因为没有名字
消息队列(Message Queue)
消息队列,就是一个消息的链表,是一系列保存在内核中消息的列表。用户进程可以向消息队列添加消息,也可以向消息队列读取消息。
共享内存
共享内存允许两个或多个进程共享一个给定的存储区,这一段存储区可以被两个或两个以上的进程映射至自身的地址空间中,一个进程写入共享内存的信息,可以被其他使用这个共享内存的进程,通过一个简单的内存读取操作读出,从而实现了进程间的通信;
采用共享内存进行通信的一个主要好处是效率高,因为进程可以直接读写内存,而不需要任何数据的拷贝,对于像管道和消息队里等通信方式,则需要再内核和用户空间进行四次的数据拷贝,而共享内存则只拷贝两次:一次从输入文件到共享内存区,另一次从共享内存到输出文件。
在进程间通信的过程中,如果使用管道、消息队列等通信方式,数据需要在内核和用户空间之间进行交换。这个过程需要经过四次数据拷贝:
- 发送进程把数据从用户空间拷贝到内核缓冲区中;
- 接收进程从内核缓冲区中把数据拷贝到用户空间中;
- 接收进程把确认信息从用户空间拷贝到内核缓冲区中;
- 发送进程从内核缓冲区中把确认信息拷贝到用户空间中。
共享内存通信方式只需要两次拷贝,是因为它避免了进程间数据的复制,将一块物理内存映射到多个进程的虚拟地址空间,进程之间直接读写这块物理内存即可。因此,共享内存的数据在不同进程间共享,不需要复制到每个进程的地址空间中,减少了数据的拷贝和传输次数,提高了通信效率。共享内存的实现一般需要使用进程间同步的方式来保证共享数据的正确性。
在 Linux 下,可以使用 shmget、shmat 和 shmdt 等系统调用来创建和操作共享内存。
1 |
|
信号量
它是一个计数器。信号量用于实现进程间的互斥与同步,而不是用于存储进程间通信数据。
套接字(Socket):套接字是一种网络通信协议,可以实现不同主机之间的进程通信。
线程通信与进程通信的区别
线程通信和进程通信是两种不同的通信机制,用于实现多个线程或多个进程之间的数据传递和协作。它们之间的主要区别如下:
- 上下文切换开销:
- 线程通信:
线程属于同一进程,它们共享相同的地址空间,因此在线程之间进行通信时,上下文切换的开销较小。线程之间可以直接访问共享内存,数据的传递和同步比较高效。 - 进程通信:
进程之间拥有独立的地址空间,彼此之间不能直接访问对方的内存。进程通信涉及到内核态和用户态之间的切换,因此上下文切换的开销相对较大,通信的性能较低。
- 线程通信:
- 同步机制:
- 线程通信:线程之间可以使用互斥锁、条件变量等同步机制,来保护共享资源的访问,实现线程之间的同步和协作。
- 进程通信:进程通信涉及到不同进程之间的数据传递,因此需要使用一些特定的通信机制,如管道、消息队列、共享内存等,来实现进程之间的同步和数据传递。
死锁
死锁(Deadlock)是多个进程或线程因争夺资源而陷入的一种僵局,每个进程都在等待其他进程释放资源,从而导致所有进程都无法继续执行。死锁的形成条件主要有四个:
互斥条件(Mutual Exclusion):每个资源最多只能由一个进程或线程占用,其他进程或线程必须等待释放。请求与保持条件(Hold and Wait):进程在保持自己的资源的同时,还在请求其他进程拥有的资源。不可剥夺条件(No Preemption):已经分配给一个进程的资源不能被强制性地剥夺,只能由进程自己释放。环路等待条件(Circular Wait):存在一个进程等待链,每个进程都在等待下一个进程所占用的资源。
以下是一些可能产生死锁的场景:
- 多线程资源竞争:多个线程同时访问共享资源,并且在保持自己资源的同时还请求其他线程的资源,形成死锁。
- 进程间通信:在进程间进行消息传递时,如果进程之间存在相互等待对方消息的情况,可能导致死锁。
- 交叉锁依赖:多个线程或进程之间按照不同的顺序请求多个锁,导致产生死锁。
为了避免死锁,可以采取以下几种策略:
- 破坏死锁条件:破坏死锁产生的四个条件中的任何一个,即可避免死锁。例如,使用资源分配策略确保资源的有序分配,避免环路等待。
- 使用资源优先级:通过为资源设置优先级,保证资源在请求时按照优先级顺序分配,避免发生死锁。
- 限制资源的最大持有时间:设置资源的最大持有时间,超过该时间则自动释放资源,避免不可剥夺条件导致的死锁。
- 死锁检测与恢复:采用死锁检测算法,定期检查系统中是否发生死锁,如果检测到死锁,使用死锁恢复算法解除死锁。
- 避免长时间持有资源:尽量避免长时间持有资源,减少死锁的发生概率。
- 协调资源请求顺序:在多线程或多进程中,协调资源请求的顺序,避免交叉锁依赖的情况。
用户空间与内核空间
用户空间与内核空间指的是不同的内存地址空间,用于划分操作系统的运行环境,便于执行不同类型的代码和访问不同的资源。
- 用户空间(User Space): 用户空间是操作系统给应用程序分配的内存区域,用于运行用户编写的应用程序。用户空间通常位于高内存地址,以防止应用程序错误地访问操作系统核心的内存区域。
- 内核空间(Kernel Space): 内核空间是操作系统核心的运行环境,其中包含了操作系统的各种功能、服务和驱动程序。内核空间通常位于低内存地址,而且是受保护的,应用程序无法直接访问。
操作系统使用==内核态(Kernel Mode)和用户态(User Mode)==来管理内核空间和用户空间的访问权限。在内核态下运行的代码可以访问内核空间,而在用户态下运行的代码只能访问用户空间。当应用程序需要执行操作系统的核心功能(例如进行系统调用)时,会从用户态切换到内核态,操作系统核心会执行相应的操作,然后再切换回用户态。
在现代操作系统中,==内核空间和用户空间的划分是为了实现多任务和资源隔离==。通过限制用户空间的访问权限,操作系统可以确保应用程序不会直接影响到核心的稳定性和安全性。
数据在内核与用户空间的拷贝问题
当 Web 服务器处理网络数据时,通常需要将数据从网络套接字读取到内核空间,然后再将数据从内核空间复制到用户空间,以便应用程序进行处理。这两次数据拷贝涉及内核与用户空间之间的数据传输,这可能会导致性能损耗。
iovec 的使用
为了减少数据拷贝带来的性能开销,Linux 提供了 iovec 结构体,==用于在用户空间和内核空间之间传递多块非连续的数据==。iovec 可以在一次系统调用中读取或写入多个不同位置的数据,从而减少数据在内核和用户空间之间的拷贝次数。
1 | struct iovec { |
iovec(I/O向量)和readv()函数用于在Socket读取数据时进行高效的数据传输和拷贝;
readv()函数是一个系统调用,用于从文件描述符(包括Socket)中读取数据到指定的iovec数组。该函数支持一次读取多个非连续的数据块,从而减少了多次系统调用和数据拷贝的开销。
下面是readv()函数的函数签名:
1 | size_t readv(int fd, const struct iovec *iov, int iovcnt); |
四、数据库
数据库连接问题
自然连接:是一种很自然的连接,没有指定连接条件,但是连接语句会自动检索两个表R,S的相同名称的列;
如果不是相同名称,则连接退化为笛卡尔积:
1 | select * from employee natural join works_on |
内连接:当自然连接匹配成功时就是内连接
1 | select * from employee inner join works_on on employee.Ssn = works_on.Essn |
外连接:分为左右外连接与全外连接,但是Mysql并不支持全外连接;
左外连接:
1.左表中的每个元组必须出现在result中
2.如果没有匹配的元组,为右表的属性添加NULL值
1 | select * from employee left outer join department on employee.Ssn = department.Mgr_ssn |
右外连接:
1 | select * from department right outer join employee on employee.Ssn = department.Mgr_ssn |
GROUP BY的相关使用
常用的聚合函数:
1 | 1.MAX:返回某列的最大值 |
1 | select sum(sal),avg(sal) from emp; |
聚合函数只作用非null,因为null数据不参与运算
1 | select avg(comm),avg(ifnull(comm,0)) from emp; |
**GROUP BY **
GROUP BY 语句根据一个或多个列对结果集进行分组。在分组的列上我们通常配合 COUNT, SUM, AVG等函数一起使用。
求部门工资总和
1
select deptno,sum(sal) from emp group by deptno;
查询每个部门工资大于1500的的人数
1
select deptno,count(*) from emp where sal >1500 group by deptno;
HAVING
HAVING用于分组后的再次筛选,只能用于分组
求工资总和大于9000的部门,并按照工资总和排序
1
2select deptno,sum(sal) total from emp group by deptno having sum(sal) >9000
order by sum(sal) asc;
having和where区别:
HAVING允许我们在聚合后的结果中进行条件过滤,而WHERE则适用于对非聚合列的条件过滤。
请注意,使用HAVING的前提是进行了GROUP BY分组,因为HAVING是用于对聚合后的分组结果进行过滤。如果没有进行GROUP BY,那么使用WHERE子句是更合适的选项。
1 | 1.having是分组后,where是分组前 |
关键字的书写顺序如下:
1 | 1.select |
1 | select deptno,sum(sal) total from emp where sal>1000 group by deptno having sum(sal) >9000 |
SQL查询的目的是从emp表中选择满足薪资大于1000的员工记录,然后按照部门对薪资进行分组,并计算每个部门的总薪资。最后,只有当某个部门的总薪资超过9000时,该部门的记录才会包含在结果中,并按照总薪资的升序进行排序。
参考链接:
MySQL 的架构共分为两层:Server 层和存储引擎层
SQL 查询语句执行过程
- 连接器:经过 TCP 三次握手建立连接(MySQL 是基于 TCP 协议进行传输),管理连接、校验用户身份;
- 查询缓存:查询语句如果命中查询缓存则直接返回,否则继续往下执行。MySQL 8.0 已删除该模块;
- 解析 SQL,通过解析器对 SQL 查询语句进行词法分析、语法分析,然后构建语法树,方便后续模块读取表名、字段、语句类型;
- 执行 SQL:执行 SQL 共有三个阶段:
- 预处理阶段:检查表或字段是否存在;将
select *中的*符号扩展为表上的所有列。 - 优化阶段:基于查询成本的考虑, 选择查询成本最小的执行计划;
- 执行阶段:根据执行计划执行 SQL 查询语句,从存储引擎读取记录,返回给客户端;
- 预处理阶段:检查表或字段是否存在;将
索引
索引的定义就是帮助存储引擎快速获取数据的一种数据结构,形象的说就是索引是数据的目录。
- 按「数据结构」分类:B+tree索引、Hash索引、Full-text索引。
- 按「物理存储」分类:聚簇索引(主键索引)、二级索引(辅助索引)。
- 按「字段特性」分类:主键索引、唯一索引、普通索引、前缀索引。
什么是聚簇索引? 找到了索引就找到了需要的数据,那么这个索引就是聚簇索引,所以主键就是聚簇索引,修改聚簇索引其实就是修改主键。 什么是非聚簇索引? 索引的存储和数据的存储是分离的,也就是说找到了索引但没找到数据,需要根据索引上的值(主键)再次回表查询,非聚簇索引也叫做辅助索引。
所谓的存储引擎,说白了就是如何存储数据、如何为存储的数据建立索引和如何更新、查询数据等技术的实现方法;InnoDB 是在 MySQL 5.5 之后成为默认的 MySQL 存储引擎;
在创建表时,InnoDB 存储引擎会根据不同的场景选择不同的列作为索引:
- 如果有主键,默认会使用主键作为聚簇索引的索引键(key);
- 如果没有主键,就选择第一个不包含 NULL 值的唯一列作为聚簇索引的索引键(key);
- 在上面两个都没有的情况下,InnoDB 将自动生成一个隐式自增 id 列作为聚簇索引的索引键(key)
B+Tree 存储千万级的数据只需要 3-4 层高度就可以满足,这意味着从千万级的表查询目标数据最多需要 3-4 次磁盘 I/O(把读取一个节点当作一次磁盘 I/O 操作),所以B+Tree 相比于 B 树和二叉树来说,最大的优势在于查询效率很高,因为即使在数据量很大的情况,查询一个数据的磁盘 I/O 依然维持在 3-4次。
树形存储与磁盘IO关系
磁盘IO时间 = 寻道 + 磁盘旋转 + 数据传输时间
从磁盘读取数据时,系统会将逻辑地址发给磁盘,磁盘将逻辑地址转换为物理地址(哪个磁道,哪个扇区)。 磁头进行机械运动,先找到相应磁道,再找该磁道的对应扇区,扇区是磁盘的最小存储单元。
(寻道时间) 首先接收到要读取的数据的物理位置, 传动臂将读写头定位到数据对应的磁道, 一般这个寻道的时间单位为 ms.
(旋转时间) 定位到对应磁道上后, 接着等待读写头定位到该磁道上数据对应的扇区的第一个字节.
(传输时间) 从磁盘读出或者写入数据, 通常这个时间是最低的.

索引在磁盘上的存储
每个InnoDB表都有一个称为聚集索引的特殊索引,该索引是按照表的主键构造的一棵B+树。
根据示例数据构建如图所示聚簇索引;

叶子节点存放了整张表的所有行数据。- 非叶子节点并不存储行数据,是为了能
存储更多索引键,从而降低B+树的高度,进而减少IO次数。 - 聚集索引的存储在物理上并不是连续的,每个数据页在不同的磁盘块,通过一个双向链表来进行连接
==查找:假设要查找数据项6==
- 把根节点由磁盘块0加载到内存,发生一次IO,在内存中用二分查找确定6在3和9之间;
- 通过指针P2的磁盘地址,将磁盘2加载到内存,发生第二次IO,再在内存中进行二分查找找到6,结束。
这里只进行了两次IO,实际上,每个磁盘块大小为4K,3层的B+树可以表示上百万的数据,也就是每次查找只需要3次IO,所以索引对性能的提高将是巨大的。
参考链接:https://juejin.cn/post/6844903856388718606
主键索引的 B+Tree 和二级索引的 B+Tree 区别
- 主键索引的 B+Tree 的叶子节点存放的是实际数据,所有完整的用户记录都存放在主键索引的 B+Tree 的叶子节点里;
- 二级索引的 B+Tree 的叶子节点存放的是主键值,而不是实际数据。
回表:先检二级索引中的 B+Tree 的索引值(商品编码,product_no),找到对应的叶子节点,然后获取主键值,然后再通过主键索引中的 B+Tree 树查询到对应的叶子节点,然后获取整行数据。这个过程要查两个 B+Tree 才能查到数据;
1 | select * from product where product_no = '0002'; |
覆盖索引:查询的数据是能在二级索引的 B+Tree 的叶子节点里查询到结果,这时就不用再查主键索引;
1 | select id from product where product_no = '0002'; |
为什么 MySQL InnoDB 选择 B+tree 作为索引的数据结构?
1、B+Tree vs B Tree
B+Tree 只在叶子节点存储数据,而 B 树 的非叶子节点也要存储数据,所以 B+Tree 的单个节点的数据量更小,在相同的磁盘 I/O 次数下(特定大小的内存缓冲区,B+树可以将更多的节点加载到内存中),能查询更多的数据。
从而在相同数量的磁盘I/O操作下,提供更高的查询吞吐量和性能。这使得B+树在处理大规模数据和频繁查询的场景下非常有效。
另外,B+Tree 叶子节点采用的是双链表连接,适合 MySQL 中常见的基于范围的顺序查找,而 B 树无法做到这一点。
B+ 树有大量的冗余节点(所有非叶子节点都是冗余索引),这些冗余索引让 B+ 树在插入、删除的效率都更高,比如删除根节点的时候,不会像 B 树那样会发生复杂的树的变化;
2、B+Tree vs Hash
Hash 在做等值查询的时候效率贼快,搜索复杂度为 O(1)。
但是 Hash 表不适合做范围查询,它更适合做等值的查询,这也是 B+Tree 索引要比 Hash 表索引有着更广泛的适用场景的原因。
索引按字段特性分类
从字段特性的角度来看,索引分为主键索引、唯一索引、普通索引、前缀索引。
主键索引:建立在主键字段上的索引,通常在创建表的时候一起创建,一张表最多只有一个主键索引,索引列的值不允许有空值;
唯一索引:建立在 UNIQUE 字段上的索引,一张表可以有多个唯一索引,索引列的值必须唯一,但是允许有空值;
在创建表时,创建唯一索引的方式如下:
1 | CREATE TABLE table_name ( |
建表后,如果要创建唯一索引,可以使用这面这条命令:
1 | CREATE UNIQUE INDEX index_name |
普通索引:建立在普通字段上的索引,既不要求字段为主键,也不要求字段为 UNIQUE;
前缀索引:对字符类型字段的前几个字符建立的索引,而不是在整个字段上建立的索引,前缀索引可以建立在字段类型为 char、 varchar、binary、varbinary 的列上。
使用前缀索引的目的是为了减少索引占用的存储空间,提升查询效率。
事务篇
事务的特性
- 原子性(Atomicity):一个事务中的所有操作,要么全部完成,要么全部不完成,不会结束在中间某个环节,而且事务在执行过程中发生错误,会被回滚到事务开始前的状态;
- 一致性(Consistency):是指事务操作前和操作后,数据满足完整性约束,数据库保持一致性状态。(比如转账前后总金额不变)
- 隔离性(Isolation):数据库允许多个并发事务同时对其数据进行读写和修改的能力,隔离性可以防止多个事务并发执行时由于交叉执行而导致数据的不一致,==因为多个事务同时使用相同的数据时,不会相互干扰==,每个事务都有一个完整的数据空间,对其他并发事务是隔离的。
- 持久性(Durability):事务处理结束后,对数据的修改就是永久的,即便系统故障也不会丢失。
InnoDB 引擎通过什么技术来保证事务的这四个特性的呢?
持久性是通过 redo log (重做日志)来保证的;
原子性是通过 undo log(回滚日志) 来保证的;
隔离性是通过 MVCC(多版本并发控制) 或锁机制来保证的;
一致性则是通过持久性+原子性+隔离性来保证;
并行事务会引发什么问题?
在同时处理多个事务的时候,就可能出现脏读(dirty read)、不可重复读(non-repeatable read)、幻读(phantom read)的问题。
脏读(dirty read):一个事务「读到」了另一个「未提交事务修改过的数据」
不可重复读(non-repeatable read):在一个事务内多次读取同一个数据,如果出现前后两次读到的数据不一样的情况,就意味着发生了「不可重复读」现象。
假设有 A 和 B 这两个事务同时在处理,事务 A 先开始从数据库中读取小林的余额数据,然后继续执行代码逻辑处理,在这过程中如果事务 B 更新了这条数据,并提交了事务,那么当事务 A 再次读取该数据时,就会发现前后两次读到的数据是不一致的,这种现象就被称为不可重复读。
幻读(phantom read):在一个事务内多次查询某个符合查询条件的「记录数量」,==如果出现前后两次查询到的记录数量不一样的情况==,就意味着发生了「幻读」现象。
事务隔离级别是怎么实现的?
SQL 标准提出了四种隔离级别来规避以上三种现象,隔离级别越高,性能效率就越低,这四个隔离级别如下:
- 读未提交(read uncommitted),指一个事务还没提交时,它做的变更就能被其他事务看到;
- 读提交(read committed),指一个事务提交之后,它做的变更才能被其他事务看到;
- 可重复读(repeatable read),指一个事务执行过程中看到的数据,一直跟这个事务启动时看到的数据是一致的,==MySQL InnoDB 引擎的默认隔离级别==;
- 串行化(serializable );会对记录加上读写锁,在多个事务对这条记录进行读写操作时,如果发生了读写冲突的时候,后访问的事务必须等前一个事务执行完成,才能继续执行;
这四种隔离级别具体是如何实现的呢?
对于「读未提交」隔离级别的事务来说,因为可以读到未提交事务修改的数据,所以直接读取最新的数据就好了; 对于「串行化」隔离级别的事务来说,通过加读写锁的方式来避免并行访问; 对于「读提交」和「可重复读」隔离级别的事务来说,它们是通过 Read View 来实现的,它们的区别在于创建 Read View 的时机不同,==Read View 可以理解成一个数据快照==,就像相机拍照那样,定格某一时刻的风景。「读提交」隔离级别是在「每个语句执行前」都会重新生成一个 Read View,而「可重复读」隔离级别是「启动事务时」生成一个 Read View,然后整个事务期间都在用这个 Read View。
Read View 在 MVCC 里如何工作的?
MVCC(多版本并发控制):通过「版本链」来控制并发事务访问同一个记录时的行为;用于「读提交」和「可重复读」隔离级别的实现
MySQL 有哪些锁?
五、算法与数据结构
背包总结
解题思路:
1.确定dp的含义
2.递推公式
3.初始化
4.确定遍历顺序
01背包问题
dp[i][j] 表示从下标为[0-i]的物品里任意取,放进容量为j的背包,价值总和最大是多少。
dp[i][j] = max(dp[i - 1][j], dp[i - 1][j - weight[i]] + value[i]);
//初始化 dpvector<vector
for(intj = weight[0]; j <= bagweight; j++) {
dp[0][j] = value[0];
}
滚动数组
dp[j] = max(dp[j], dp[j - weight[i]] + value[i]);
遍历顺序需要注意
二维dp遍历的时候,背包容量是从小到大,而一维dp遍历的时候,背包是从大到小。
1 | for(int i = 0; i < weight.size(); i++) { // 遍历物品 |
倒序遍历是为了保证物品i只被放入一次!。但如果一旦正序遍历了,那么物品0就会被重复加入多次
分割等和子集 -> 背包问题
目标和(求方案数)
1和0
注意求最值与求方案数的区别
1 | class Solution { |
完全背包问题
物品无限,可以重复加入;
无需再考虑内层循环从大到小遍历的情况;
对于求最值问题:无需考虑双重循环的顺序
对于求方案数量问题:考虑求排列数量(先遍历容量)还是求组合数量(先遍历物品)
零钱兑换求最少硬币数(最值问题),求方案数量(排列数问题,先遍历物品)
多重背包理论
有N种物品和一个容量为V 的背包。第i种物品最多有Mi件可用,每件耗费的空间是Ci ,价值是Wi 求解将哪些物品装入背包可使这些物品的耗费的空间 总和不超过背包容量,且价值总和最大
每件物品最多有Mi件可用,把Mi件摊开,其实就是一个01背包问题了
打家劫舍1,2,3
树形dp的实现思路
状态dp
买卖股票的最佳时机1,2,3,4
剑指 Offer 30. 包含min函数的栈
定义栈的数据结构,请在该类型中实现一个能够得到栈的最小元素的 min 函数在该栈中,调用 min、push 及 pop 的时间复杂度都是 O(1)。
关键思路:辅助栈思想 stack<int> x_stack; stack<int> min_stack;min_stack栈顶元素记录 x_stack对应当前状态的最小元素,可以保证O(1)时间复杂度;
HDU ACM:1446 计算直线的交点数
http://acm.hdu.edu.cn/showproblem.php?pid=1466
1 | Description |
1 | 1.四条直线全部平行,无交点 |
1 | n条直线的最多可能交点数为n*(n-1)/2,即前n个自然数的和。 |
1 |
|
约瑟夫环——公式法(递推公式)
f(N,M)=(f(N−1,M)+M)%N
f(N,M)表示,N个人报数,每报到M时杀掉那个人,最终胜利者下标(故其编号为f(N,M)+1)
如果不删除数组元素,可以使用一个bool类型的数组来标记每个人是否已经被排除。修改后的代码如下:
1 |
|
注意不能返回局部对象的引用或者指针;
血量问题
血量为n,k个技能对应的伤害为1到k,技能可以无限重复使用,有多少种方案杀死
完全背包问题:求排列数,先遍历血量再遍历物品
1 | cppCopy code |
解释如下:
- 首先,我们定义状态 dp[i] 表示血量为 i 的怪物被杀死的方案数。
- 初始状态:当怪物血量为 0 时,它已经被杀死了,所以 dp[0] = 1。
- 状态转移:对于血量为 i 的怪物,它可以通过使用任意一种技能造成 1 到 k 点的伤害,因此我们枚举技能造成的伤害 j,并累加 dp[i-j] 到 dp[i] 上。状态转移方程为:dp[i] = sum{dp[i-j]} (1 <= j <= k && j <= i)。
- 最终答案:当怪物的血量为 n 时,它被杀死的方案数为 dp[n]。
牛顿迭代法求平方根代码实现
要求是这样:输入一个数,输出其对应的平方根。假设输入的数是 m,则其实是求一个 x 值
$$
使其满足 x^2 = m,令f(x) = x^2 - m ,
$$
其实就是求方程 f(x) = 0 的根那么 f(x) 的导函数是 f’(x) = 2x。那么 f(x) 函数的曲线在
$$
(xn,xn^2 - m)
$$
处的切线的斜率是:2xn,因此切线方程是:
$$
y = 2xn (x - xn) + xn^2 - m
$$
故切线与x轴的交点是:xn+1 = (xn + m / xn ) / 2
根据牛顿迭代法,首先应该在曲线 f(x) 上任意选取一点,做切线。那么,我们直接把输入的数 m,作为选取的点的横坐标,即 x0 = m,然后根据上式进行迭代。
1 | // err 是允许的误差 |
LRU缓存算法
1 | // 实现双向链表结构 |
快排;稳定版本快排;三路快排;
1 | int pivot(std::vector<int>& nums, int left, int right); // 普通快速排序 |
堆排序
1 |
|
合并两个有序链表
1 | /** |
合并k个有序链表
给定一棵二叉树和target,输出路径之和=target的路径
最长递增子序列
1 | class Solution { |
最长无重复子串
1 | class Solution { |
最长公共子串
题目描述:给定两个字符串,求出他们之间最长相同子字符串长度。
解题步骤:采用动态规划,与求解最长公共子序列类似,只不过状态定义要修改。
1、 状态定义:dp[i][j]表示以s1[i]和s2[j]为最后一个元素的最长公共子串,如果最长公共子串存在,公共子串的最后一个元素一定是s1[i]或者s2[j]他们相等。
2、 状态转移方程:
如果s1[i]和s2[j]相等,那么:dp[i][j] = dp[i-1][j-1]+1;
如果s1[i]和s2[j]不相等,则:dp[i][j] = 0;
3、 初始化:初始dp[0][j]和dp[i][0]都为0
4、 输出:dp[i][j]的最大值
————————————————
原文链接:https://blog.csdn.net/zy450271923/article/details/105301611
最长公共子序列
1 | class Solution { |
编辑距离
给你两个单词 word1 和 word2, 请返回将 word1 转换成 word2 所使用的最少操作数 。
你可以对一个单词进行如下三种操作:
- 插入一个字符
- 删除一个字符
- 替换一个字符
1 | class Solution { |
题目
字符串A编辑成字符串B可有三种操作: 插入、删除、修改,对应的代价为c0,c1,c2,给出字符串A和字符串B以及各自长度m、n,返回字符串A编辑成字符串B的最小代价。
分析
状态dp[i][j]表示A[0,…i-1]编辑为B[0,…j-1]需要的代价,i,j指的是当前A、B中的字符个数
边界值讨论
i = 0时,表示从空串编辑为B[0,…j-1],需要插入j个元素,dp[0][j] = c0*j
j = 0时,表示从A[0,..i-1]编辑为空串,需要删除i个元素,dp[i][0] = c1* i;
一般情况讨论
其他情况中A[0,…i-1]编辑为B[0,…j-1],有以下两种情况:
(一)A[i-1] == B[j-1]时,最后一个元素不用动,只用考虑A[0,…i-2]编辑为B[0,…j-2]需要的代价,dp[i][j] = dp[i-1][j-1]
(二)A[i-1]!=B[j-1]时,又可以分成以下三种情况:
1、从A[0,…i-2]编辑为B[0,…j-1],再删除A[i-1]
2、从A[0,…i-1]编辑为B[0,…j-2],再插入B[j-1]
3、从A[0,…i-2]编辑为B[0,…j-2],再将A[i-1]修改为B[j-1]
在以上三种情况中取最小值。
————————————————
原文链接:https://blog.csdn.net/gulaixiangjuejue/article/details/85249973
单例模式
饿汉模式: 在类加载时就创建了实例
实例对象 instance 被定义为 static 局部变量,而且是在静态成员函数 getInstance() 内部进行初始化
1 |
|
懒汉模式: 单例实例在第一次使用时才会被创建,线程不安全,需要加入互斥锁保证线程安全;
懒汉模式中的 static Singleton* instance 并不会在类加载时创建。它只是一个==指针==,它的初始值为 nullptr,表示还没有创建实际的单例实例。
1 |
|
场景题
内存限制下查找数组的重复数
==哈希==,如果数据量很大,采用位方式(俗称位图)存储数据是常用的思路
- 题目要求:给定一个数组,包含从1到N的整数,N最大为32000,数组可能还有重复值,且N的取值不定,若只有4KB的内存可用,该如何打印数组中所有重复元素。
如果只有4KB的空间,那么只能寻址842^10个比特,这个值比32000要大的,因此我们可以创建32000比特的位向量(比特数组),其中一个比特位置就代表一个整数。
利用这个位向量,就可以遍历访问整个数组。如果发现数组元素是v,那么就将位置为v的设置为1,碰到重复元素,就输出一下。
1 |
|
当 pos 的值为 35 时,我们来看一下 get 和 set 函数是如何处理的。
get函数:
pos / 32计算出pos对应的bits数组的索引:35 / 32 = 1,所以我们需要查看bits[1]。pos & 0x1f计算出pos对应的bits数组索引内的位偏移:35 & 0x1f = 3,所以我们需要查看bits[1]的第 3 位。1 << (pos & 0x1f)生成一个只有第 3 位为 1 的值,即 00001000(二进制)。bits[pos / 32] & (1 << (pos & 0x1f))操作将bits[1]中的第 3 位与上述生成的值进行位与操作。如果结果非 0,那么表示该位置已经被设置为 1。如果结果为 0,表示该位置没有被设置为 1。
set函数:
pos / 32计算出pos对应的bits数组的索引:35 / 32 = 1,所以我们需要设置bits[1]。pos & 0x1f计算出pos对应的bits数组索引内的位偏移:35 & 0x1f = 3,所以我们需要设置bits[1]的第 3 位。1 << (pos & 0x1f)生成一个只有第 3 位为 1 的值,即 00001000(二进制)。bits[pos / 32] |= (1 << (pos & 0x1f))操作将bits[1]中的第 3 位与上述生成的值进行位或操作,将该位置的位设置为 1。
综上所述,在这个例子中,当 pos 为 35 时,get 函数会返回 false,因为 bits[1] 的第 3 位是 0,表示这个位置没有被设置为 1。而调用 set 函数后,bits[1] 的第 3 位会被设置为 1。
- 题目要求:给定一个输入文件,包含40亿个非负整数,请设计一个算法,产生一个不存在该文件中的整数,假设你有1GB的内存来完成这项任务。
假设用哈希表来保存出现过的数,如果 40 亿个数都不同,则哈希表的记录数为 40 亿条,存一个 32 位整数需要 4B,所以最差情况下需要 40 亿*4B=160 亿字节,大约需要16GB 的空间,这是不符合要求的。
如果数据量很大,采用位方式(俗称位图)存储数据是常用的思路,那位图如何存储元素的呢? 我们可以使用 bit map 的方式来表示数出现的情况。具体地说, 是申请一个长度为 4 294 967 295 的 bit 类型的数组 bitArr(就是boolean类型),bitArr 上的每个位置只可以表示 0 或1 状态。8 个bit 为 1B,所以长度为 4 294 967 295 的 bit 类型的数组占用 500MB 空间,这就满足题目给定的要求了。
那怎么使用这个 bitArr 数组呢?就是遍历这 40 亿个无符号数,遇到所有的数时,就把 bitArr 相应位置的值设置为 1。例如,遇到 1000,就把bitArr[7000]设置为 1。
遍历完成后,再依次遍历 bitArr,看看哪个位置上的值没被设置为 1,这个数就不在 40 亿个数中。例如,发现 bitArr[8001]==0,那么 8001 就是没出现过的数,遍历完 bitArr 之后,所有没出现的数就都找出来了。
位存储的核心是:我们存储的并不是这40亿个数据本身,而是其对应的位置。
使用10MB来存储
1 | 如果现在只有 10MB 的内存,此时位图也不能搞定了,我们要另寻他法。这里我们使用分块思想,时间换空间,通过两次遍历来搞定。 |
总结一下进阶的解法:
根据 10MB 的内存限制,确定统计区间的大小,就是第二次遍历时的 bitArr 大小。
利用区间计数的方式,找到那个计数不足的区间,这个区间上肯定有没出现的数。
对这个区间上的数做 bit map 映射,再遍历bit map,找到一个没出现的数即可。
- 题目要求:有一个包含 20 亿个全是 32 位整数的大文件,在其中找到出现次数最多的数。要求,内存限制为 2GB。
一共有 20 亿个数,哪怕只是一个数出现了 20 亿次,用 32 位的整数也可以表示其出现的次数而不会产生溢出,所以哈希表的 key 需要占用 4B,value 也是 4B。那么哈希表的一条记录(key,value)需要占用 8B,当哈希表记录数为 2 亿个时,需要至少 1.6GB 的内存。
如果 20 亿个数中不同的数超过 2 亿种,最极端的情况是 20 亿个数都不同,那么在哈希表中可能需要产生 20 亿条记录,这样内存会不够用,所以一次性用哈希表统计 20 亿个数的办法是有很大风险的。
解决办法是把包含 20 亿个数的大文件用哈希函数分成 16 个小文件,根据哈希函数的性质,==同一种数不可能被散列到不同的小文件上==,同时每个小文件中不同的数一定不会大于 2 亿种, 假设哈希函数足够优秀。然后对每一个小文件用哈希表来统计其中每种数出现的次数,这样我们就得到了 16 个小文件中各自出现次数最多的数,还有各自的次数统计。接下来只要选出这16 个小文件各自的第一名中谁出现的次数最多即可。
六、项目
子宫动脉栓塞仿真
Unet、Res_Unet 原理与区别
UNET主要由编码器和解码器两个部分组成。编码器通过多次的卷积和池化操作来提取图像的特征信息,得到一个高维度的特征图。解码器则通过反卷积和上采样等操作将编码器输出的特征图还原为与输入图像相同大小的分割结果;
Res_Unet是在Unet的基础上增加了残差连接。残差连接是一种特殊的跳跃连接方式,可以将网络的层数增加到很深。残差连接可以直接将输入特征图加到输出特征图上,使得网络可以学习到残差信息,从而提高网络性能。
Marching Cubes算法和拉普拉斯网格优化算法
Marching Cubes算法是一种用于从三维数据中提取等值面的方法,用于将三维数据(如医学图像)转换为三维表面网格表示;
基本思想是将三维数据集分成许多小的三维单元格,并根据每个单元格中数据的值来确定表面的位置和形状。具体而言,Marching Cubes算法将每个单元格分成8个小单元格,并使用每个小单元格的数据值(例如,体素密度)来确定表面的位置和形状。根据每个小单元格中数据值的组合,Marching Cubes算法确定表面的形状,例如球形、柱状、平面或其他复杂形状。最后,通过将所有单元格的表面连接在一起,生成一个完整的三维表面网格表示。
Marching Cubes算法的优点是可以处理不规则的、非均匀的、非线性的三维数据,生成高质量、准确的表面网格表示。它还可以在可接受的时间内处理大规模数据集。然而,Marching Cubes算法也存在一些缺点,例如可能产生表面拓扑错误、边界不完整或重叠的表面片段等问题;
拉普拉斯网格优化算法是一种用于三维模型的平滑算法,它的目的是将模型中不平滑的部分进行平滑,以得到更加自然的曲面。项目中利用了拉普拉斯矩阵,对模型进行网格优化。通过计算每个顶点的平均值来调整其位置,对于一个给定的顶点,它的平均值是指所有相邻顶点的位置之和再除以相邻顶点数。使用拉普拉斯方程的离散形式将平均值加权到原始位置上得到新的位置;
unity粒子系统
Unity的粒子系统是一个强大的工具,可以用来创建各种流体效果。它的实现原理主要是基于GPU的粒子渲染技术,具体来说,它会通过发射器不断地生成粒子,并根据每个粒子的属性和发射器的控制来更新粒子的状态。然后,所有的粒子会被传递给GPU进行计算和渲染,最终生成不同的特效效果;
webserver
介绍
TinyWebServer主要的目的是实现一个轻量级的HTTP服务器完成对浏览器的连接请求进行解析处理,处理完之后给浏览器客户端返回一个响应。服务器后端的处理方式使用socket通信,利用IO多路复用技术可以同时监听多个请求,使用线程池处理请求,模拟Reactor事件模式,主线程只负责监听IO,监听到有事件之后,将IO请求对象放入请求队列交给工作线程处理,睡眠在请求队列上的工作线程被唤醒进行数据读取以及逻辑处理。
整个服务的程序结构
Server启动后,通过创建一个主线程套接字并绑定到指定的IP地址和端口。然后,它进入一个循环,等待传入的连接请求;- 当有新的连接请求到达时,
Server接受连接返回一个用于通信的Socket,并创建一个新的HTTPCONN实例来处理该连接。
改进过程中遇到的难点
socket
Socket是一种用于在计算机之间进行通信的机制,它提供了一套标准的网络通信接口,使得不同的进程或者不同的计算机可以通过这一接口来进行数据交换。通过Socket接口,可以使用TCP或者UDP等协议在网络中进行通信。
通过Socket接口实现通信过程:
服务端
1 | 1. 创建一个用于监听的套接字 |
客户端
1 | 1. 创建一个用于通信的套接字(fd) |
而eventpoll是Linux系统中一种高效的I/O多路复用机制,它可以同时监听多个文件描述符的状态,当其中任何一个文件描述符发生变化时,可以及时通知应用程序进行处理,从而避免了轮询等低效的方式。在网络编程中,eventpoll通常被用于监听多个socket的状态,以便及时处理传输的数据。
简单的TCP网络程序
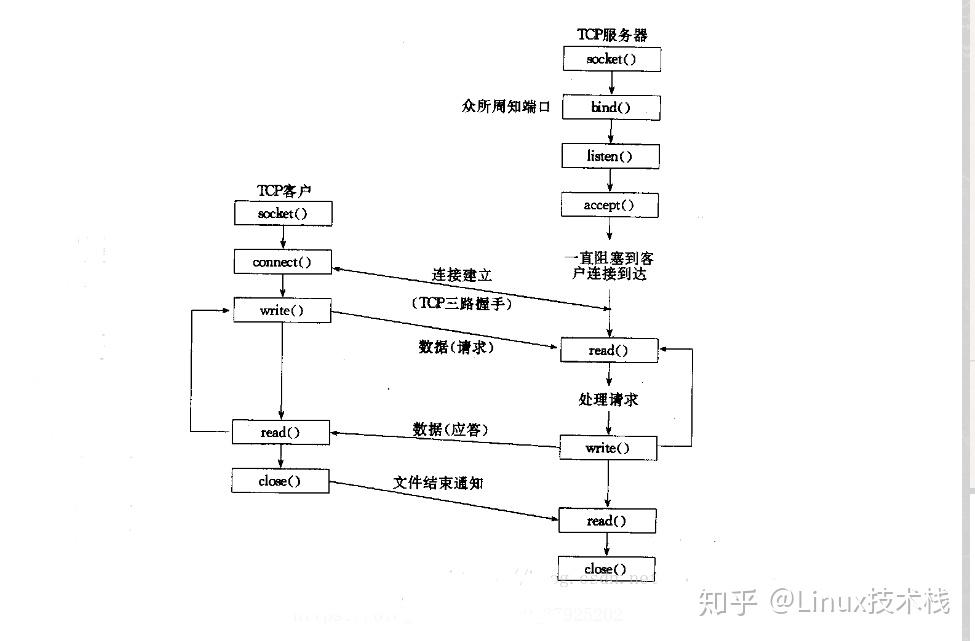
UDP网络程序
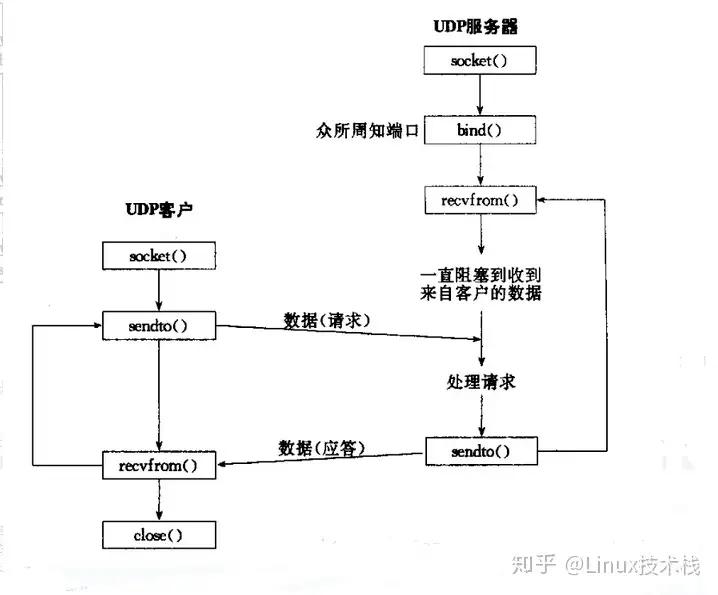
相对与TCP来说,UDP安全性差,面向无链接。所以UDP地实现少了连接请求与接收连接的操作;
TCP收发数据用函数send()和recv(),或者read()和write();
UDP收发数据用函数recvfrom(),sendto();
IO复用技术
是一种同步IO模型,实现同时监听多个文件描述符的IO事件,一旦某个IO事件就绪,就能够通知应用程序进行相应的读写操作;主要IO多路复用技术有select,poll和epoll;
select
工作流程:
首先构造一个关于文件描述符的列表readfds,将要监听的文件描述符添加到该列表中,通过FD_SET将readfds中对应的文件描述符设为1
调用select,将文件描述符列表readfds copy到内核空间,监听该列表中的文件描述符,轮询感兴趣的fd,没有数据到来则select阻塞,直到这些文件描述符中的一个或者多个进行IO操作时,内核将对应位置为1并将结果返回用户空间。
用户空间遍历文件描述符列表readfds,通过FD_ISSET检测对应的fd是否置位,如果置位则调用read读取数据。
优点:可以监听多个文件描述符
缺点:
最大可监听文件描述符有上限,由fd_set决定(一般为1024)
需要将fd_set在用户态和内核态之间进行copy,开销大
无法精确知道哪些fd准备就绪,每次都需要遍历所有的fd
文件描述符列表集合不能重用,每次都需要重置。
poll
poll跟select实现方式差不多,区别在于
- 没有最大可监听fd限制,因为其底层通过链表实现;
poll内核通过revents来设置某些事件是否触发,所有每次不需要再重置
1 | struct pollfd { |
epoll
epoll是一种比select,poll更加高效的IO多路复用技术。epoll有三个重要接口:epoll_create, epoll_ctl, epoll_wait。
首先通过epoll_create在内核创建一个新的创建eventpoll结构体。
这个在内核创建的结构体有两个重要的数据,一个是需要检测的文件描述符信息,底层是红黑树, 增删改时间复杂度都为logn。另一个是就绪列表,存放所有有IO事件到来的fd(其共用红黑树的节点),底层是双向链表。
epoll_ctl是对这个实例进行管理,包括插入,删除和更新三个操作。
其中插入是使用socket fd及其关注的事件构造结构体,并插入到eventpoll中,同时会给内核中断处理程序注册一个回调函数,告诉内核,如果这个句柄的中断到了,就把它放到准备就绪list链表中。删除就是将socket fd对应的节点从eventpoll中删除,更新就是修改socket fd相关的信息,比如更改其所监听的事件等。
epoll_wait为检测函数,是一个阻塞的接口,如果就绪列表中有事件到来,就会将就绪事件copy到用户空间(通过epoll_event结构体),并返回事件的数量。没有数据就sleep,等到timeout时间到了即使没有数据也返回。
对于select和poll来说,所有文件描述符都是在用户态被加入其文件描述符集合的,每次调用都需要将整个集合拷贝到内核态;epoll则将整个文件描述符集合维护在内核态,每次添加文件描述符的时候都都需要执行一个系统调用。
系统调用的开销是很大的,而且在有很多短期活跃连接的情况下,epoll可能会慢于select和poll由于这些大量的系统调用开销。
epoller_->Wait() 方法在内部会使用红黑树和双链表来管理文件描述符,并根据事件的发生情况进行处理。当调用 epoller_->Wait() 方法时,它会先从红黑树中获取所有需要监视的文件描述符,然后等待这些文件描述符上的事件发生。一旦有事件发生,就会将相应的文件描述符放入双链表的就绪链表中,最后将已经就绪的文件描述符返回给调用者。
为什么ET模式下一定要设置非阻塞?
阻塞IO:当我们对一个阻塞的文件描述符(阻塞IO)进行读写时,如果没有数据到来,就会卡在调用的函数上面直到有数据可以进行读写,Socket中可能阻塞的API:accept, recv,connect,send;
非阻塞IO:读写一个非阻塞文件描述符的时候,无论是否可读写都会 立即返回结果。
· 成功:返回对应的结果。
· 失败:设置对应的errno
LT模式:
如果文件描述符上有数据可读或可写缓冲区可写,那么在整个数据读完或写完之前,epoll_wait() 会一直返回该文件描述符上有可读或可写事件。
LT 模式是默认模式,通常使用非阻塞模式来监听文件描述符。即使文件描述符被设置为阻塞模式,在 LT 模式下,epoll_wait() 仍然会立即返回,并告知文件描述符上有可读、可写或异常事件,而不会阻塞线程。这意味着 LT 模式下,非阻塞模式和阻塞模式对于 epoll_wait() 的行为没有区别。
ET模式:
在 ET 模式下,当一个文件描述符上有事件发生时,epoll_wait() 只会通知一次,并且只有在文件描述符状态从无事件变为有事件时才会触发通知,所以需要使用循环一次性将读写操作完成。
==阻塞IO+ while循环==,当最后一个数据读取完之后是跳不出循环的while(1){int len = recv();}最后一次读不到进行了阻塞,卡在这了;
如果是==非阻塞IO+while循环==,当数据读取完之后recv就会立即返回-1,并且将errno进行设置,不会被卡在这里,性能提升;
故而一般是ET+搭配非阻塞IO,ET在很大程度上减少了epoll事件被重复触发的次数,因此效率比LT高。
监听套接字为什么要设置成非阻塞的?

从图中可知,connect()会先于accep()函数返回。
在listen_fd阻塞的情况下,当一个连接到来的时候,监听套接字可读,此时,我们稍微等一段时间之后再调用accept()。就在这段时间内,客户端设置linger选项(l_onoff = 1, l_linger = 0),然后调用了close(),那么客户端将不经过四次挥手过程,通过发送RST报文断开连接。服务端接收到RST报文,系统会将排队的这个未完成连接直接删除,此时就相当于没有任何的连接请求到来, 而接着调用的accept()将会被阻塞,会导致整个线程阻塞在这里,无法继续处理其他已建立连接的读写操作或其他任务,直到另外的新连接到来时才会返回。
EPOLLONESHOT
EPOLLONESHOT 是 Linux 下 epoll 事件注册时的一个标志,用于控制事件的触发方式。当一个文件描述符上的事件被设置为 EPOLLONESHOT 后,该事件在触发一次后将被自动禁用,直到重新调用 epoll_ctl 重新设置该事件的触发条件。
使用 EPOLLONESHOT 主要是为了避免多个线程同时处理同一个文件描述符的同一个事件,从而保证事件的原子性和顺序性。
发送一个HTTP请求,服务器生成响应,怎么判断这个响应是否完整然后浏览器进行渲染?
在发送 HTTP 请求后,服务器会生成响应并将其返回给客户端(浏览器)。浏览器接收到响应后,会根据响应头中的信息来判断响应是否完整,并根据响应的内容进行渲染。
在 HTTP 响应中,有两个关键的头部字段用于判断响应是否完整:
- Content-Length:这个字段表示响应正文的长度,以字节为单位。浏览器会根据 Content-Length 字段的值来判断响应是否完整。如果 Content-Length 字段存在,并且与实际接收到的响应正文长度相符,那么浏览器会认为响应是完整的。
- Transfer-Encoding:这个字段表示传输编码方式,常见的值有 “chunked” 和 “identity”。如果响应中使用了 chunked 传输编码,那么浏览器会根据每个数据块的长度来判断响应是否完整。
当浏览器确定响应是完整的后,它会根据响应头中的 Content-Type 字段来判断响应的内容类型,然后使用相应的渲染引擎来处理和显示响应的内容。比如,对于 HTML 内容,浏览器会使用 HTML 渲染引擎来解析 HTML 标记并显示页面内容。
在渲染页面的过程中,浏览器会下载并加载页面中引用的其他资源,比如 CSS、JavaScript、图片等。这些资源会根据响应头中的信息来判断是否完整,然后进行渲染和显示。
总结起来,浏览器通过解析响应头中的 Content-Length 字段和 Transfer-Encoding 字段来判断响应是否完整,然后根据 Content-Type 字段来选择相应的渲染引擎对响应内容进行解析和渲染。这样,浏览器就能够正确显示服务器返回的页面内容。
项目里如果一个HTTP请求不完整怎么判断?
如果一个 HTTP 请求不完整,即服务器未能完整地接收到该请求,通常可以根据以下几种方式来判断:
- Content-Length 头部:HTTP 请求头部中的 Content-Length 字段表示请求正文的长度,以字节为单位。服务器可以通过 Content-Length 字段来判断请求是否完整。如果请求头部中包含 Content-Length 字段,并且服务器成功接收了指定长度的请求正文数据,则可以认为请求是完整的。
- Transfer-Encoding 头部:HTTP 请求头部中的 Transfer-Encoding 字段表示传输编码方式,常见的值有 “chunked” 和 “identity”。如果请求中使用了 chunked 传输编码,服务器可以根据每个数据块的长度来判断请求是否完整。
- Connection 头部:HTTP 请求头部中的 Connection 字段可以指定是否使用持久连接(keep-alive)。如果请求使用了持久连接,服务器可以根据 Connection 头部来判断是否继续等待接收后续的请求数据。
- 超时机制:服务器可以设置一个合适的超时时间,当超过该时间仍未接收到完整的请求数据时,可以判断请求不完整,并对其进行适当的处理。
在实际应用中,服务器通常会结合多种方法来判断请求是否完整,以确保请求数据的完整性和准确性。如果服务器检测到请求不完整,可以返回适当的错误码(如 400 Bad Request)或其他错误信息,以便客户端重新发送完整的请求。
内存映射是有名还是匿名?
内存映射可以有两种形式:有名内存映射和匿名内存映射。
- 有名内存映射(Named Memory Mapping):有名内存映射是通过在文件系统中创建一个特定的文件,然后将该文件映射到内存中。这样多个进程可以通过文件名来访问和共享同一块内存区域,从而实现进程间的共享数据。有名内存映射通常用于进程间的通信。
- 匿名内存映射(Anonymous Memory Mapping):匿名内存映射是将一块未命名的内存区域映射到进程的地址空间中,该内存区域没有对应的文件,仅仅用于进程内部的数据交换。匿名内存映射通常用于进程内部的数据共享,或者在父子进程之间共享数据。
在 Linux 系统中,有名内存映射可以通过 mmap 函数,并指定文件描述符和映射大小来实现;匿名内存映射可以通过 mmap 函数,并将文件描述符设置为 MAP_ANONYMOUS 来实现。
1 |
|
两种事件的处理模式
Reactor模式
要求主线程(I/O处理单元)只负责监听文件描述符上是否有事件发生,有的话就立即将该事件通知工作线程(逻辑单元),将 socket 可读可写事件放入请求队列,交给工作线程处理。除此之外,主线程不做任何其他实质性的工作。读写数据,接受新的连接,以及处理客户请求均在工作线程中完成。
使用同步 I/O(以 epoll_wait 为例)实现的 Reactor 模式的工作流程是:
主线程往 epoll 内核事件表中注册 socket 上的读就绪事件。
主线程调用 epoll_wait 等待 socket 上有数据可读。
当 socket 上有数据可读时, epoll_wait 通知主线程。主线程则将 socket 可读事件放入请求队列。
睡眠在请求队列上的某个工作线程被唤醒,它从 socket 读取数据,并处理客户请求,然后往 epoll内核事件表中注册该 socket 上的写就绪事件。
当主线程调用 epoll_wait 等待 socket 可写。
当 socket 可写时,epoll_wait 通知主线程。主线程将 socket 可写事件放入请求队列。
睡眠在请求队列上的某个工作线程被唤醒,它往 socket 上写入服务器处理客户请求的结果。
Proactor模式
Proactor 模式将所有 I/O 操作都交给主线程和内核来处理(进行读、写),工作线程仅仅负责业务逻
辑。使用异步 I/O 模型(以 aio_read 和 aio_write 为例)实现的 Proactor 模式
区别及优缺点
Reactor 是非阻塞同步网络模式,感知的是就绪可读写事件。在每次感知到有事件发生(比如可读就绪事件)后,就需要应用进程主动调用 read 方法来完成数据的读取,也就是要应用进程主动将 socket 接收缓存中的数据读到应用进程内存中,这个过程是同步的,读取完数据后应用进程才能处理数据。
优缺点:
Reactor实现相对简单,对于耗时短的处理场景处理高效;事件的串行化对应用是透明的,可以顺序的同步执行而不需要加锁;
Reactor处理耗时长的操作会造成事件分发的阻塞,影响到后续事件的处理;
Proactor 是异步网络模式, 感知的是已完成的读写事件。在发起异步读写请求时,需要传入数据缓冲区的地址(用来存放结果数据)等信息,这样系统内核才可以自动帮我们把数据的读写工作完成,这里的读写工作全程由操作系统来做,并不需要像 Reactor 那样还需要应用进程主动发起 read/write 来读写数据,操作系统完成读写工作后,就会通知应用进程直接处理数据。
优缺点
Proactor性能更高,这种设计允许多个任务并发的执行,从而提高吞吐量;并可执行耗时长的任务(各个任务间互不影响)
Proactor实现逻辑复杂;依赖操作系统对异步的支持。
Reactor 可以理解为来了事件操作系统通知应用进程,让应用进程来处理,而 Proactor 可以理解为来了事件操作系统来处理,处理完再通知应用进程。
线程池设计与实现
ThreadPool类定义了一个线程池,它可以在构造函数中指定线程数量。线程池的主要作用是接受任务并分配给可用线程来执行。Pool结构是线程池的内部私有结构,包含以下成员:std::mutex mtx:用于保护线程池内部数据结构的互斥锁。std::condition_variable cond:用于线程之间的条件变量,用于通知等待中的线程任务可用或线程池关闭。bool isClosed:标志线程池是否已关闭。std::queue<std::function<void()>> tasks:任务队列,用于存储待执行的任务。
在线程池的构造函数中,它会创建指定数量的工作线程,每个线程会不断地从任务队列中取出任务并执行。这些工作线程会一直运行,直到线程池被销毁。
构造函数中的循环使用
std::thread创建了多个工作线程。每个线程都会执行一个lambda函数,该函数会在获取任务时执行任务,并且在任务队列为空且线程池未关闭时等待条件变量通知。析构函数会在销毁线程池时被调用。它首先将线程池标记为已关闭(
pool_->isClosed = true),然后通过条件变量通知所有等待的线程,以便它们可以退出。这确保线程池的资源得到正确释放。AddTask方法用于向线程池提交任务。它会将任务添加到任务队列,并通过条件变量通知等待中的线程有新任务可执行。
这段代码实现了一个基本的线程池,它管理一组工作线程,可以接受任务并在这些线程中执行。通过使用互斥锁和条件变量,它确保线程之间的协同工作,同时处理任务队列和线程池的关闭。这种线程池可用于提高并发性能,减少线程创建和销毁的开销。
std::shared_ptr<Pool> pool_;
是一个成员变量,它是一个指向 Pool 结构的 std::shared_ptr 智能指针。这里之所以使用 std::shared_ptr,是为了确保线程池的正确生命周期管理,以防止内存泄漏和资源泄漏,并允许多个地方引用相同的线程池实例。
下面是为什么使用 std::shared_ptr 的一些理由:
生命周期管理:
std::shared_ptr允许多个对象(例如,线程池的构造函数和析构函数)共享对Pool实例的引用。这确保只有在最后一个引用被销毁时,Pool实例才会被销毁。这有助于确保线程池在使用它的所有地方都保持有效。避免资源泄漏:如果线程池是通过裸指针或其他方式管理的,可能会出现资源泄漏的情况,因为线程池在某些情况下可能无法被正确销毁。使用
std::shared_ptr可以确保在不再需要线程池时自动释放它。线程安全:
std::shared_ptr本身是线程安全的,多个线程可以同时访问和修改共享的引用计数。这确保了在多线程环境中对线程池的引用操作是安全的。方便的拷贝和传递:
std::shared_ptr可以方便地进行拷贝和传递,而不需要手动管理引用计数。这使得在不同地方使用线程池更加方便。
总之,使用 std::shared_ptr 可以简化线程池的生命周期管理,提高代码的可维护性,并确保在线程池的所有地方都可以正确引用和使用它,同时保证资源的正确释放。这是一种常见的 C++ 内存管理和资源管理模式。
pool_->cond.notify_one() :
- 通知等待中的一个线程:如果有线程因为等待条件变量而被阻塞,它们中的一个会被唤醒。这是因为
notify_one()会唤醒一个等待的线程,但不会唤醒所有。 - 继续执行等待的线程:被唤醒的线程将检查条件是否满足,如果满足条件,它将继续执行;否则,它将继续等待。
在线程池的 AddTask 方法中,pool_->cond.notify_one() 用于通知等待的线程,以便它们可以检查任务队列中是否有新任务可用。如果有一个或多个线程正在等待条件变量(例如,在调用 pool_->cond.wait(locker) 时),则其中的一个线程将被唤醒,以便它可以获取新的任务并执行它。
唤醒哪个阻塞的线程的具体机制可以分为以下几种情况:
不确定性唤醒(Non-deterministic Wakeup):
在一般情况下,当多个线程等待同一个条件变量时,调度器通常会选择其中一个线程唤醒,但不能确定唤醒的顺序。这就是为什么在使用
notify_one()时,不能确定哪个线程会被唤醒。优先级(Priority):
有些操作系统的线程调度器可能会考虑线程的优先级,更高优先级的线程可能更容易被唤醒。但这取决于操作系统和调度器的实现。
先到先服务(First-Come-First-Served):
在某些情况下,调度器可能会按照线程进入等待状态的顺序来唤醒线程,这就是所谓的“先到先服务”原则。但这也不是所有情况下都成立的。
随机性(Randomness):
在某些情况下,线程唤醒的顺序可能会具有随机性,这是为了防止线程饥饿和提高公平性。
互斥锁(Mutex)和条件变量(Condition Variable)
互斥锁用于保护共享资源的访问,而条件变量用于在线程之间传递信息和控制线程的执行流程。它们通常一起使用,以实现复杂的多线程同步和协作。,它们有以下主要区别:
作用和用途:
互斥锁:主要用于保护共享资源的访问,确保同一时刻只有一个线程可以访问共享资源。当一个线程获得互斥锁时,其他线程会被阻塞,直到互斥锁被释放。
条件变量:用于在线程之间传递信息和控制线程的执行流程。它通常与互斥锁结合使用,允许线程等待某个条件的发生,并在条件满足时被唤醒。
主要操作:
互斥锁:主要有两个操作,即锁定(Lock)和解锁(Unlock)。线程可以尝试锁定互斥锁,如果锁已被其他线程锁定,则会被阻塞,直到锁可用。
条件变量:主要有三个操作,即等待(Wait)、通知(Notify)和广播(Broadcast)。线程可以等待在条件变量上,等待某个条件的满足。其他线程可以通过通知或广播来唤醒等待的线程。
关联性:
互斥锁:通常与共享资源一起使用,用于保护对共享资源的访问,防止多个线程同时修改共享资源,从而避免数据竞争和不一致性。
条件变量:通常与互斥锁结合使用。条件变量允许线程等待某个条件的发生,而这个条件通常与共享资源的状态相关。条件变量的等待通常包含在临界区内,以确保线程在等待和被唤醒期间不会出现竞态条件。
等待机制:
互斥锁:不提供等待机制。如果一个线程无法获取互斥锁,它会被阻塞,直到互斥锁可用。
条件变量:提供了等待和唤醒机制。线程可以等待在条件变量上,直到其他线程通过通知或广播唤醒它们。
使用场景:
互斥锁:适用于任何需要保护共享资源的情况,如临界区保护、互斥访问共享数据等。
条件变量:适用于需要线程等待特定条件的情况,如生产者-消费者问题、线程间通信、任务调度等。
HTTP请求解析
现自动增长的缓冲区
小根堆实现的定时器
timer_->add(fd, timeoutMS_, std::bind(&WebServer::CloseConn_, this, &users_[fd]));
为fd对应的连接添加一个超时定时器,超时时间为timeoutMS_毫秒。如果在timeoutMS_毫秒内没有接收到客户端的数据,则执行回调函数:std::bind(&WebServer::CloseConn_, this, &users_[fd])这个回调函数的作用是:调用WebServer对象的CloseConn_方法关闭fd对应的连接。
定时器的核心逻辑:通过维护一个定时器堆和时间戳来管理定时器,所有的功能实现都是围绕堆展开的。主要通过调整堆实现添加定时器、 删除定时器、调整定时器等功能。tick()函数通过不断检查堆顶是否超时来执行定时回调。
timer_是作为全局定时器存在的,它由主线程创建,但不属于任何特定的工作线程。各连接创建的定时器事件由timer_统一管理
timer_是HeapTimer类型的对象,在WebServer构造函数中实例化。它负责存储和管理所有的定时器事件。_
每个新连接通过void WebServer::AddClient_(int fd, sockaddr_in addr)方法添加到WebServer中。在该方法中,通过timer_->add()为连接创建一个定时器事件,并将其添加到timer_中。timer_会为每个定时器事件维护其超时时间timeout。并通过时间循环反复检查当前时间,判断哪些定时器事件已经超时。
timer_设计为unique_ptr主要有以下好处:
- 可以灵活重置指向其他定时器,方便功能变更。
- 生命周期绑定到WebServer,但可以被重置完全控制。
- 避免了手动管理内存的麻烦,减少内存泄漏的可能。
- 体现了RAII的思想,简化了定时器资源的管理。
- 易读易维护,符合现代C++代码的习惯。
利用单例模式与阻塞队列实现异步的日志系统
在这个WebServer构造函数中,日志系统被设计为:
单例模式:Log::Instance()返回日志系统的唯一实例,简化了日志系统的创建和使用。
阻塞队列:日志信息通过阻塞队列logQueSize缓存,然后由日志线程 asynchronously 写入文件。
异步写入:日志线程会不断从阻塞队列中取出日志消息,写入日志文件。而业务线程只需要将日志消息插入队列,不等待写入完成。
所以,日志系统的工作流程是
WebServer构造函数调用Log::Instance()初始化日志系统,设置日志级别logLevel和日志文件路径等信息。
业务线程(如工作线程)产生日志消息后,调用LOG_INFO或LOG_ERROR将消息插入阻塞队列。
不等待日志消息写入完成,业务线程可以继续处理其他任务。
日志线程会反复检查阻塞队列,如果有日志消息,则取出并写入日志文件。
日志消息的生成和写入是异步的,通过阻塞队列实现解耦。
那么,这种日志系统设计的优点是:
- 单例模式简化了日志系统的使用,只需要调用Log::Instance()即可获得日志对象。
- 异步写入提高了业务线程的执行效率,不会被日志写入阻塞。
- 阻塞队列作为缓冲,可以防止日志消息溢出,并解耦日志的生成和写入。
- 日志系统的工作线程独立于其他任何业务线程,可独立运行。
在WebServer的日志系统中,日志线程是专门用于异步写入日志消息的线程。它与主线程和其他业务线程(如工作线程)的关系如下:
- 日志线程在WebServer构造函数中被创建,用于异步写入日志消息。它独立运行,不属于任何业务线程。
- 主线程通过InitEventMode_、InitSocket_等方法完成服务器环境初始化工作。如果初始化成功且开启日志,还会通过Log::Instance()初始化日志系统。
- 日志系统初始化后,主线程继续监听连接和分配任务。日志线程开始通过阻塞队列读取日志消息并写入日志文件。
- 各业务线程(工作线程等)运行并产生日志消息,通过LOG_INFO或LOG_ERROR将消息插入阻塞队列,并不等待写入。
- 日志线程会不断从阻塞队列读取新的日志消息,写入日志文件完成异步写入功能。
- 即使业务线程结束,只要日志系统存在,日志线程会继续运行读取插入队列的日志消息。
- 日志线程与具体的业务线程无关,它仅作用于日志系统这个中间层,将日志消息从生成线程异步传递到写入线程。
所以,可以看出:
- 日志线程是WebServer构造函数创建,用于异步写入日志消息。它独立于任何业务线程运行。
- 主线程用于初始化服务器环境,包括日志系统。各业务线程用于运行业务逻辑和产生日志消息。
- 日志消息的生成属于各业务线程,但写入属于日志线程。两者之间通过阻塞队列解耦。
- 尽管业务线程结束,只要日志系统存在,日志线程会继续运行。它与特定的业务线程无直接关联。
- 日志线程作为中间层,实现了日志消息从生成线程到写入线程的异步传递。
所以,日志线程实际上充当了消息队列或中间件的角色,实现了日志系统的异步功能。
线程池的线程数量一般怎么设置?
CPU密集:
CPU密集的意思是该任务需要大量的运算,只有在真正的多核CPU上才可能得到加速,CPU密集型任务配置尽可能少的线程数量:CPU核数+1个线程的线程池
IO密集型:
即该任务需要大量的IO,即大量的阻塞。在单线程上运IO密集型的任务会导致浪费大量的CPU运算能力浪费在等待;参考公式:CPU核数*2;CPU核数 /(1 - 阻系数)(阻塞系数在0.8~0.9之间);
数据库连接池
连接池的基本思想就是在初始化时,将数据库连接对象保存在内存中,当用户需要访问数据库时,并非新建一个连接,而是从连接池中取出一个空闲的连接对象;使用完毕后,也并非直接断开连接,而是重新放到连接池中。以达到避免频繁连接断开数据库,提高数据库的处理效率。
1 | MYSQL* SqlConnPool::GetConn() { |
根据连接池的基本思想,我们设计一个数据库连接池SqlConnPool,如下:
- 单例模式,保证进程唯一
- 使用queue来管理数据库连接对象(静态大小)
- 互斥锁实现线程安全
池提供了连接对象的获取和释放接口,但是在实际使用中,需要使用者记得在使用完毕后去释放连接对象,这样的设计并不友好,因此我们添加一个数据库操作类SqlConnRAII,利用RAII来封装下数据库连接池,这样可以确保在使用完连接对象后,操作类会帮助我们析构释放对象。
并发编程中常见的三类并发问题
通常称为 “原子性”、”可见性” 和 “顺序性” 问题。
原子性(Atomicity)问题:
问题描述:原子性问题涉及到操作的不可分割性。在多线程环境中,如果一个操作被拆分成多个子操作,而其他线程可以在其中某个子操作执行期间干扰该操作,那么就可能导致不一致或错误的结果。
解决方式:使用互斥锁、原子操作、事务等机制来确保关键操作的原子性,以防止其他线程的干扰。
可见性(Visibility)问题:
问题描述:可见性问题涉及到线程之间共享数据的可见性。当一个线程修改共享变量的值时,其他线程可能无法立即看到这个变化,导致数据不一致性。
解决方式:使用同步机制(如互斥锁、volatile关键字、原子操作、条件变量等)来确保共享数据的可见性,以便一个线程对共享变量的修改对其他线程是可见的。
顺序性(Ordering)问题:
问题描述:顺序性问题涉及到操作的执行顺序。在多线程环境中,线程执行的顺序可能会受到编译器优化、CPU指令重排等因素的影响,导致不符合预期的执行顺序。
解决方式:使用同步机制来明确定义线程之间操作的执行顺序,如互斥锁、volatile关键字、内存屏障等,以确保操作按照期望的顺序执行。
这些并发问题是多线程编程中需要仔细考虑的关键问题,因为它们可能导致不确定的行为、竞态条件、数据损坏等问题。解决这些问题通常需要谨慎设计和使用同步机制,以确保多线程程序的正确性和可靠性。
举例:
volatile 的作用是告诉编译器不要对 flag 变量进行优化,确保在多线程环境中对 flag 的读取和写入不会被编译器重排或优化掉。这可以解决可见性问题,因为它确保了一个线程对 flag 的修改对其他线程是可见的。
https://zhuanlan.zhihu.com/p/552580039
七、自我介绍
下面我从两个方面进行自我介绍,
第一是我的在校经历,我本科就读于河海大学计算机科学与技术;研究生就读的是电子信息-计算机技术专业,在校期间有过学业优秀奖学金以及班级团支书、校长学生事务助理等学生工作经验,参与过两次重大的体育赛事,分别是江苏省第十九届运动会和武汉第七届世界军人运动会,在其中担任电子裁判和成绩处理工程师,负责竞赛成绩系统的测试与成绩实时展示,这两次实践经历锻炼了我对于大规模赛事下工作对接沟通的抗压能力以及赛事系统功能测试方面的经验;
第二是我的研究方向,我研究生阶段的研究方向的医学图像分割以及三维仿真,基于介入手术的背景实现了对子宫动脉血管的分割以及三维重建,并基于物理引擎实现基础的模拟;此外也有过HTTP服务器实现,CATIA二次开发、经典战例兵棋推演系统的测试等项目经验,能够熟练使用c++语言,熟悉STL、智能指针、Lambda表达式以及单例模式的实践应用;
八、测试岗位
黑盒与白盒的测试方法
黑盒测试:
在完全不考虑程序内部结构和内部特性的情况下,测试者在程序接口进行测试,它只检查程序功能是否正常,程序是否能接收输入数锯而产生正确的输出信息,并且保持外部信息(如数据库或文件)的完整性。
常用的黑盒测试方法有:等价类划分法;边界值分析法;因果图法;场景法;正交实验设计法;判定表驱动分析法;错误推测法;功能图分析法。
等价类划分是将系统的输入域划分为若干部分,然后从每个部分选取少量代表性数据进行测试。
边界值分析法是对等价类划分的一种补充,因为大多数错误都在输入输出的边界上。边界值分析就是假定大多数错误出现在输入条件的边界上,如果边界附件取值不会导致程序出错,那么其他取值出错的可能性也就很小。
白盒测试:
白盒测试是检查程序内部逻辑结构,对所有的逻辑路径进行测试,是一种穷举路径的测试方法;
常用白盒测试方法:
静态测试:不用运行程序的测试,包括代码检查、静态结构分析、代码质量度量、文档测试等等
动态测试:需要执行代码,通过运行程序找到问题,包括功能确认与接口测试、覆盖率分析、性能分析、内存分析等。
反问
- 软件测试的核心竞争力是什么?
- 测试和开发需要怎样去沟通与结合?
九、网络编程
thread的使用
thread是一个类,可以通过创建类对象来创建一个新线程,并通过初始化来关联一个可执行对象,使线程完成特定的工作。
当创建一个线程对象后,并且给线程关联线程函数,该线程就被启动,与主线程一起运行。线程函数一般情况下可按照以下三种方式提供:
- 函数指针
- lambda表达式
- 函数对象
1 | void ThreadFunc(int a){ |
线程函数的参数是以值拷贝的方式拷贝到线程栈空间中的,因此:即使线程参数为引用类型,在线程中修改后也不能修改外部实参,因为其实际引用的是线程栈中的拷贝,而不是外部实参
1 | void ThreadFunc1(int& x){ |
join与detach
当这个线程结束的时候,可以使用detach()与join()回收线程所使用的资源:
当使用join()函数时,主调线程阻塞,等待被调线程终止,然后主调线程回收被调线程资源,并继续运行;
当使用detach()函数时,主调线程继续运行,被调线程驻留后台运行,主调线程无法再取得该被调线程的控制权。当主调线程结束时,由运行时库负责清理与被调线程相关的资源。
多线程交替打印
1 |
|
多线程对多个文件内的数字求和
1 |
|
C++确保线程安全的几种方式?代码举例
互斥锁:互斥锁是一种简单但有效的线程安全机制。它用于确保对共享资源的访问是线程安全的。
条件变量:条件变量用于等待某个条件变为真。它通常与互斥锁一起使用,以确保等待条件变量的线程不会被其他线程打断。
原子操作:原子操作是保证在多线程环境下操作是原子性的操作。这意味着操作不会被其他线程打断。
1
2
3
4
5
6
7
8
9// 定义一个原子变量
std::atomic<int> counter;
// 使用原子变量
void increment_counter() {
// 原子地增加计数器
++counter;
}线程局部存储:线程局部存储是每个线程都有自己一个副本的变量。这可以防止多个线程访问同一个变量导致数据竞争。
1
2
3
4
5
6
7
8// 定义一个线程局部变量
std::thread_local int counter;
// 使用线程局部变量
void increment_counter() {
// 原子地增加计数器
++counter;
}
互斥锁
使用了 std::mutex 和 std::lock_guard<std::mutex>
std::lock_guard 是一个 RAII(Resource Acquisition Is Initialization)机制的实现,它会在构造时自动加锁,析构时自动解锁,从而确保在任何情况下都会正确地释放互斥锁,避免了因为异常或返回等情况下忘记解锁的问题。
1 |
|
- 定义互斥锁:首先需要定义一个互斥锁变量,一般使用
std::mutex类型。 - 加锁:在进入临界区前,使用
lock()或try_lock()方法来获取互斥锁的所有权。lock()方法会阻塞当前线程,直到成功获取锁,而try_lock()方法会尝试立即获取锁,如果锁已经被其他线程占有,它会立即返回而不是阻塞。 - 访问共享资源:一旦成功获取了互斥锁的所有权,当前线程就可以进入临界区,访问共享资源。
- 解锁:在临界区访问共享资源结束后,使用
unlock()方法释放互斥锁,使其他线程有机会获得锁,继续访问共享资源。
1 |
|
条件变量
1 |
|
这段代码演示了如何使用条件变量(std::condition_variable)来实现线程间的同步和通信。代码中包含一个工作线程(workerThread)和主线程(main)。它们之间通过条件变量和互斥锁来实现同步,确保工作线程在满足特定条件时被唤醒执行。
在主线程中,首先创建了一个工作线程
worker,并在工作线程开始执行前延迟2秒钟(std::this_thread::sleep_for(std::chrono::seconds(2)))。这是为了模拟在工作线程执行前需要等待的情况。接下来,主线程获取了互斥锁
mtx,并将条件变量ready设置为true。这里使用了std::lock_guard简化了互斥锁的管理。条件变量ready表示工作线程可以开始执行了。在设置了
ready后,主线程通过cv.notify_one()唤醒了等待的工作线程。notify_one()用于通知等待在条件变量上的一个线程,以便它继续执行。工作线程
workerThread中,首先获取了互斥锁mtx,然后调用cv.wait(lock, [] { return ready; })。cv.wait()是一个条件变量的等待操作,它会使得当前线程阻塞等待,直到条件变量ready的值为true。在等待期间,工作线程会释放互斥锁mtx,允许其他线程进入临界区。当主线程将
ready设置为true并调用cv.notify_one()后,工作线程收到通知被唤醒,它再次尝试获取互斥锁mtx。一旦成功获取锁,工作线程继续执行,并输出 “Worker thread is running.”。
通过这种方式,我们实现了主线程与工作线程之间的同步和通信。主线程通过设置 ready 条件变量,唤醒了工作线程的等待,并让工作线程在条件满足时继续执行。使用条件变量可以避免线程的忙等待,节省了系统资源,提高了线程的效率。
1 |
|
注意到 cv.notify_all() 用于唤醒所有等待在条件变量 cv 上的工作线程,而不再是之前的 cv.notify_one()。因为有多个工作线程在等待,我们需要全部唤醒,以确保它们都能继续执行。
Linux子进程创建没有wait操作会发生什么
在 Linux 中,如果父进程创建了子进程,而没有等待子进程终止的操作(比如使用 wait() 或 waitpid() 函数),则子进程会成为一个僵尸进程(Zombie Process)。
僵尸进程是指一个子进程已经终止(通过调用 exit() 或者由于异常终止),但是其父进程还没有对其进行回收资源的操作。在这种情况下,子进程的进程表项仍然存在,但是它已经不再运行。僵尸进程会占用系统的一些资源,包括进程号(PID)、进程表项和一部分内存。
1 |
|
cmake
- gcc
它是GNU Compiler Collection(就是GNU编译器套件),也可以简单认为是编译器,它可以编译很多种编程语言(括C、C++、Objective-C、Fortran、Java等等)。
- make
make工具可以看成是一个智能的批处理工具,它本身并没有编译和链接的功能,而是用类似于批处理的方式—通过调用makefile文件中用户指定的命令来进行编译和链接的。
- makefile
简单的说就像一首歌的乐谱,make工具就像指挥家,指挥家根据乐谱指挥整个乐团怎么样演奏,make工具就根据makefile中的命令进行编译和链接的。makefile命令中就包含了调用gcc(也可以是别的编译器)去编译某个源文件的命令。
- cmake
cmake根据一个叫CMakeLists.txt文件,可以更加简单的生成makefile文件给上面那个make用,能够跨平台生成对应平台能用的makefile,无需手动修改。
makefile编写
文件目录树
1 | makefile_t/ |
version1
1 | hello: main.cpp printhello.cpp factorial.cpp |
version2
1 | CXX = g++ |
version3
1 | CXX = g++ |
version4
1 | CXX = g++ |
.PHONY,makefile的特殊变量,用于生成“伪目标”。make中的“目标”通常指文件,但有时功能和文件名会重叠。以clean为例,我们需要clean来清除全部的中间文件,但同时我们不需要真的生成一个名为”clean”文件,所以当目标文件夹存在一个“clean”文件时,“clean”功能就不会被执行,所以需要一个”伪目标”去执行“clean”功能。
wildcard,用于防止通配符解析失败。使变量定义时,括号里的通配符仍然生效。
patsubst,用于防止替换文件解析失效。替换文件后缀。
CMakeLists.txt编写
1 | cmake_minimum_required(VERSION 3.0.0) |
 微信
微信 支付宝
支付宝


